
前言
大家好,今天来分享一下我们队(ECNU_ICA)在 2021 年字节跳动安全 AI 挑战赛色导用户识别方面的工作。
先说名次,在经历了初赛、复赛以及决赛的重重竞争,最终我们拿到了全国第七的成绩。
呜呜,虽然在决赛里是垫底的样子,但是我认为我们做的这些工作还是有一定的学习价值。
也感谢各位大佬前来观摩~
这里再放几个相关链接:
- Github 开源:https://github.com/imqxms/2021_bytedance_security_ai_track1_open
- 答辩视频:https://www.bilibili.com/video/BV1za411z75D
- 答辩 PPT:ECNU_ICA 答辩 PPT.pdf
- 技术明细:ECNU_ICA 技术明细.pdf
团队简介
放一张团队简介,我们团队横跨国内外三大高校。要问距离这么远我们是怎么结缘的,一切都源于,我们都是 imqxms. 社区的成员。
继 2020 年 7 月底,imqxms. 首次线下聚会后~ 这也算是社区成员又一次因为同一件事情聚在了一起~
哈哈哈,没有安排紧致的各种活动,大家都因为一些兴趣组成了这样一个小圈子~

赛题理解
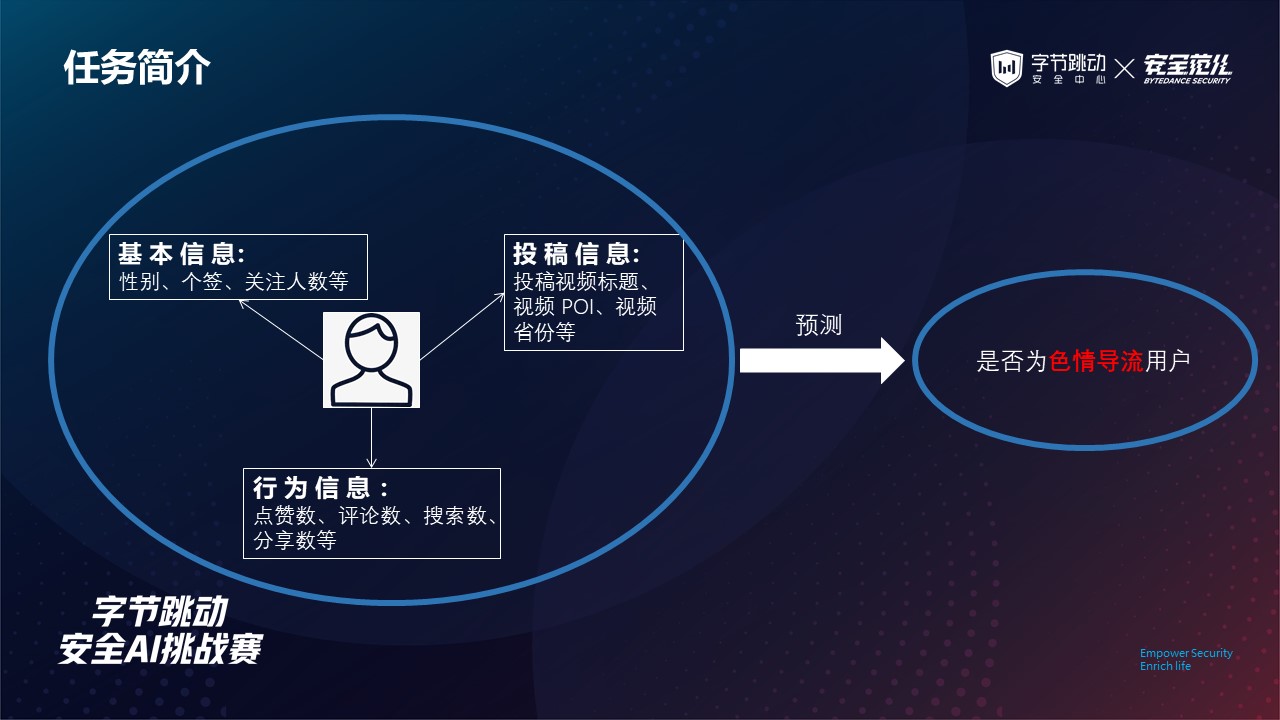
任务简介
本次赛题主要以网络黑产识别为背景,根据用户基本信息(如性别、个性签名、关注人数)、用户行为信息(如点赞数、评论数等)以及用户投稿信息来预测该用户是否为色情导流用户。
评估指标
任务的评估指标选用 F-beta,这里的 beta 为 0.3,该指标可用于权衡预测结果的精准率以及召回率。

特征工程
基础特征
这里是数据集所能提供的所有基础特征,我们将这些特征分为三类:
- 第一类是离散型特征,像省份、性别这种,类别与类别之间相关但没有顺序性的关系
- 第二类是连续型特征,像年龄、粉丝数这种,值与值之间存在明显的有序性,可以相互比较大小
- 第三类是序列型特征,这种主要包含像个性签名、视频标题一类本身不具有原子性,而是由更细的字或词根据特定顺序组合而来的信息

领域特征挖掘与构建
导流方式概览
除此以外,想要深刻的理解任务以及做出更加合理的解决方案,需要我们对当前业务以及用户导流方式有一个基本的认知。
因此,我们基于题目描述所知的信息调查了现有主流的几种用户导流方式:
- 通过视频中或者头像中的二维码诱导扫描
- 通过可提供文字的地方进行联系方式的投放(例如个性签名中的微信号等)
- 通过可提供文字的地方投放短链接诱导用户点击进入网站
- 通过诱导性话语、谐音字、象形字来描述语义并建立起的导流方式
- 通过用户间的互动行为,在一个账号的视频下通过 @、评论、转发等方式导流用户进入到下一个账号
- 利用同城功能在指定时间段投放相关信息,例如操作大批账号在抖音同城热门视频下集体评论,吸引有心之人点进主页,再根据个签中的联系方式引流到微信等平台
当然,这些导流方式有的受限于当前所提供的数据难以实现,例如视频及头像信息缺失、文本信息已做脱敏处理等。

个人主页中的导流方式
这里是关于个人主页中的一些引流方式的示例。
考虑防止被现有模型检测以及过滤,色导用户的联系方式往往会通过象形字 / 同音字或 emoji 表情的方式引出,例如『v♥』代表微信、『加薇』之类的也代表微信添加的方式,也有『+q』代表 qq 的联系方式。
有的联系方式之前使用冒号来分隔。
部分用户在个性签名中也会留有导流途径的介绍,例如『看头像找我』,而头像中则包含二维码等信息。
除了通过同音字 / 象形字 / emoji 表情引出联系方式以外,部分色导用户还会用这种手段摆明意图,例如最后一张图。
当然,也存在正常的商业导流,但其行为与色情导流的差别在于是否刻意使用语义技巧来隐藏信息。

同城导流
另外也有一些同城引流的示例,通常黑产团伙会设计好专门的话术,并且加上明显的 POI 地点,因为距离的接近,会使得导流成功的概率大大提升。
例如操作大批账号在热门视频下评论,而部分账户的个人介绍或账号名中包含着城市名,这样一批评论会吸引有心之人点进主页,再根据一些隐含的联系方式导流到其他平台。
根据调研发现,抖音『同城』功能中,深夜时段为色情导流用户的活跃期。
这些结果都表明,在现有任务所提供的数据下,如何更好的去建模个性签名、投稿时间等信息对模型提升的潜力是很大的。
但现阶段由于脱敏等缘故难以建模同音字或 emoji 等信息,因此我们考虑尽可能的基于脱敏文本挖掘有用的知识。

领域特征构建
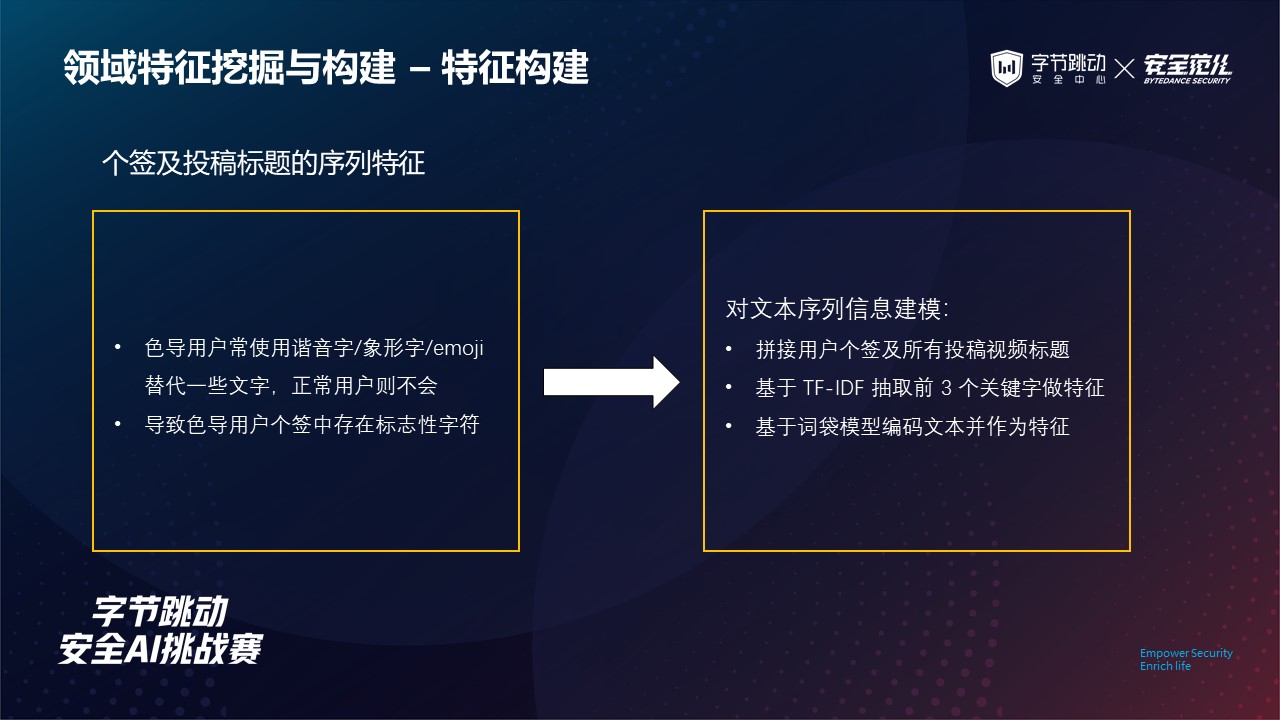
这里是具体特征构建的过程,针对个性签名以及投稿标题的序列特征,我们考虑色导用户通常使用谐音字 / 象形字 / emoji 来替代一些文字,而正常用户则不会。
这会导致色导用户个签中可能存在一些标志性的字符或短语,这些字符或短语在正常用户中出现频率很低。
因此,我们考虑拼接用户的个性签名及其所有投稿视频的标题,形成该用户的描述性文本。
然后基于 TF-IDF 算法从该描述性文本中抽取前 3 个代表性的关键字。
同时我们基于词袋模型为描述性文本进行编码,生成文本的词袋表征用于后续模型训练。
针对用户个性签名及投稿视频标题中以链接进行导流的方式,
我们设计规则来鉴别链接信息,主要是 http 及 https 两类,然后得出脱敏 index 与相关字符的一个映射关系。
根据该规则,我们提取出用户个性签名及其视频标题中是否包含链接以及包含链接的数量作为特征。

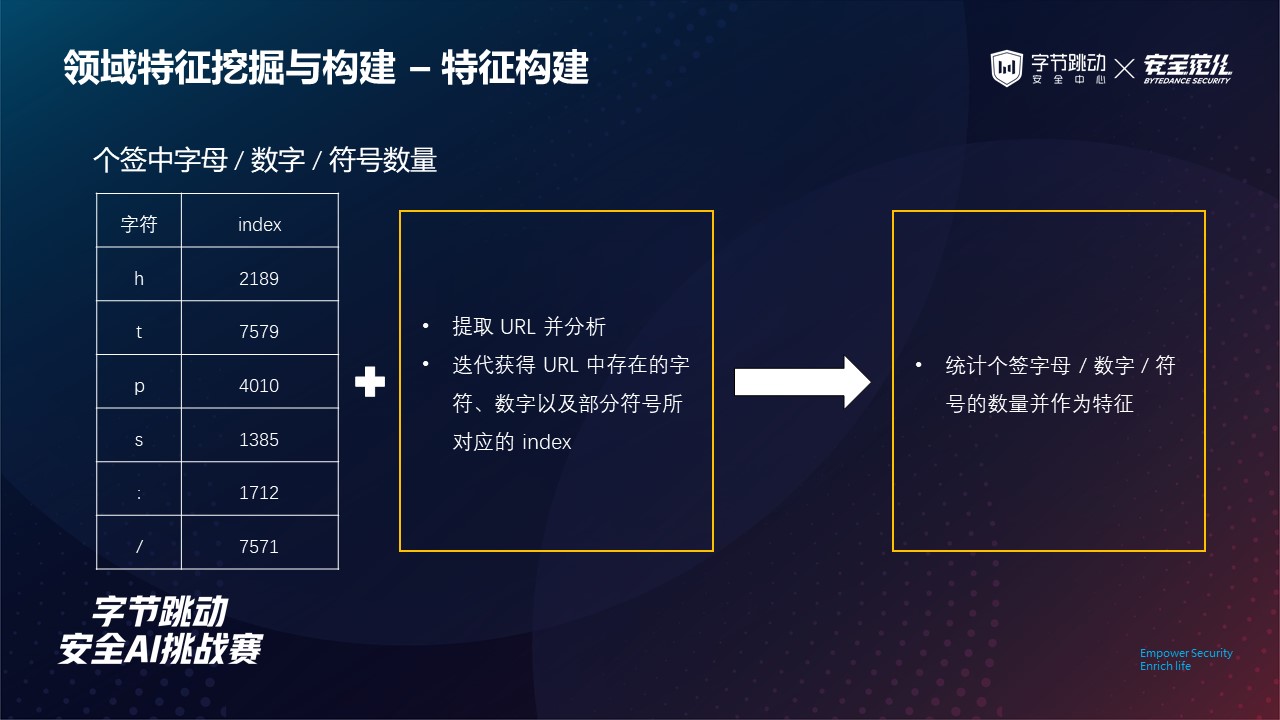
考虑到色导用户其个性签名中往往使用谐音字来隐藏信息,而谐音的一个来源则包括字母及数字。此外,有无联系方式的存在也是有无导流行为的一个鉴别依据。
因此,在上一步确定 http 及 https 相关信息后,我们基于规则提取完整链接并做进一步的分析,迭代获得了链接中存在的字符、数字以及部分符号所对应的 index,进而将个签中所包含字母 / 数字 / 符号的数量作为了特征。
特征聚合
在有了前面的基础特征和领域特征后,我们还采用特征聚合及特征交叉的方式生成新的特征。
特征聚合就是说根据现有的一个或多个离散列执行聚合操作,并统计出其余列的一些统计信息。
例如:每个用户的投稿数量、每个用户投稿地区覆盖了多少个省份 / POI、个性签名为空的用户的平均粉丝数是多少。
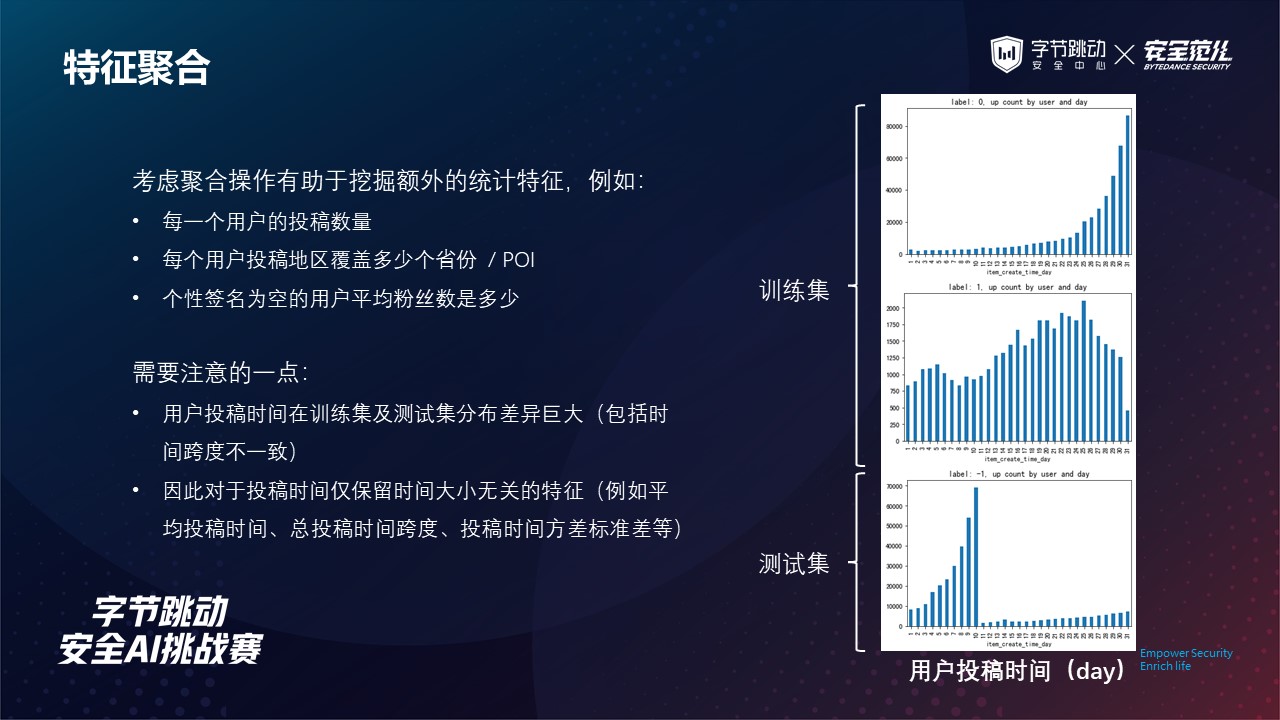
在比赛中我们发现,投稿时间这一个特征训练集与测试集之间的分布差异非常大。
在根据投稿时间的时间戳提取出一个月每一天的投稿量时,我们发现训练集中正常用户的投稿量随着月初到月末逐渐增加,而色导用户的投稿量也有着较为平滑的浮动曲线。
同样的,测试集中投稿量随着天数的增加也有一定的变化规律,但其分布与训练集差异较大。
实验中也发现了这一特征有穿越的现象(可能是构建数据集采样时出现了一些问题),因此综合考虑下最终我们仅保留了与时间大小无关的特征,例如平均投稿时间、总投稿时间跨度等。
特征交叉
此外,针对一些特定的连续型特征,我们还考虑特征之间的交互容易组合出一些更为有用的新特征,
例如播放时长 / 播放次数 = 平均播放时长、粉丝数 / 投稿数 = 平均每个投稿所获粉丝量,
因此我们考虑通过加减乘除对候选的连续型特征进行组合。

模型构建
机器学习模型
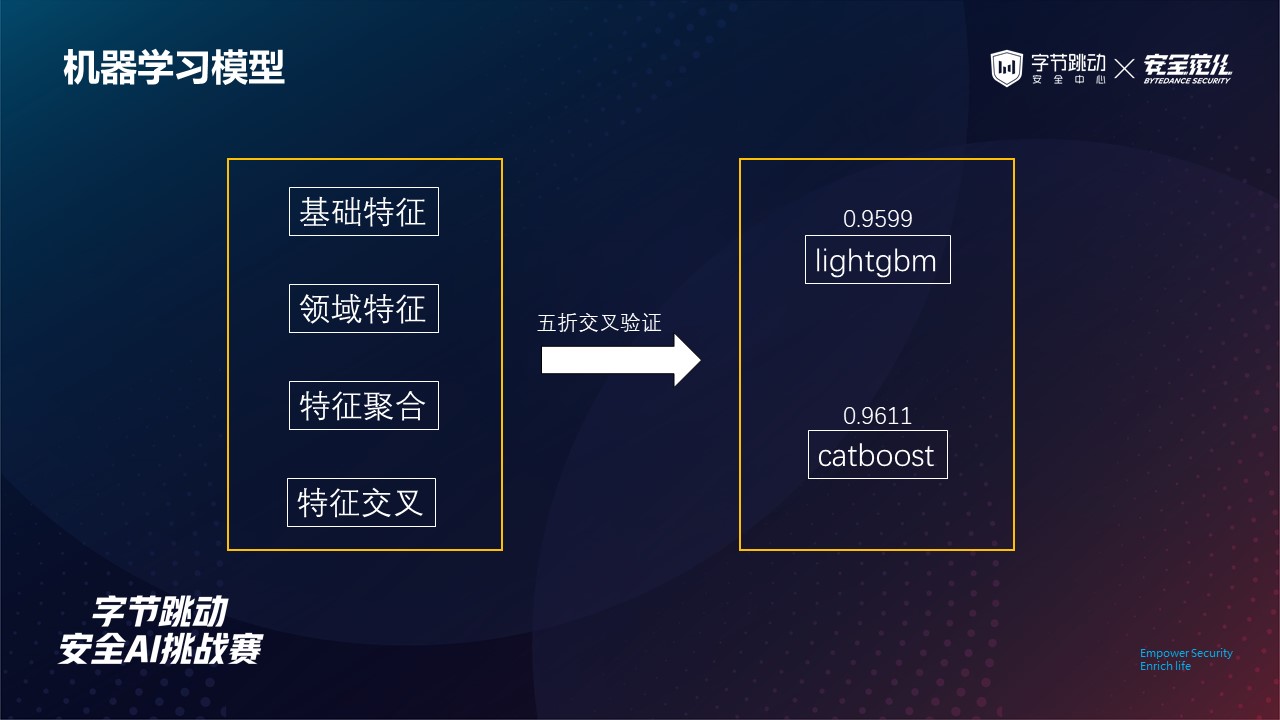
基于前面得到的基础特征、领域特征以及特征聚合与特征交叉的结果,我们使用五折交叉验证的方法训练下游的树模型,主要测试过 lgb 以及 catboost 两个模型,最终在 catboost 中取得了复赛 0.9611 的成绩。
深度学习模型
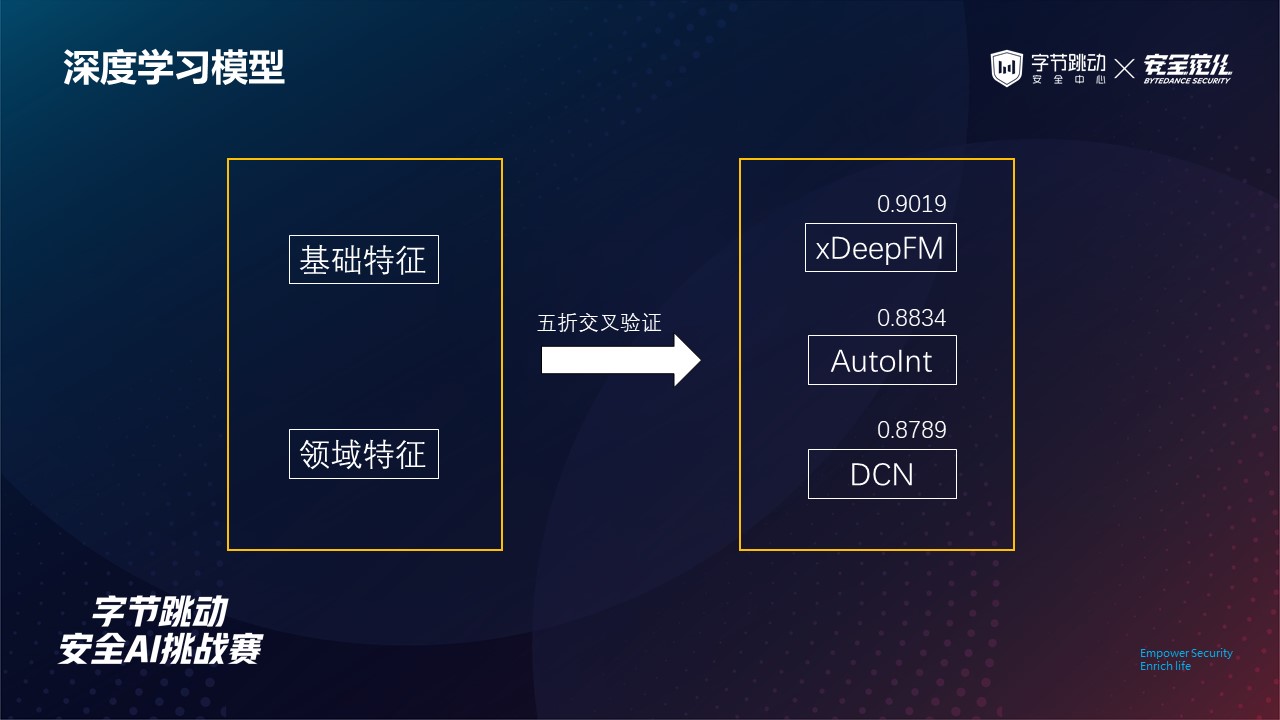
我们也尝试过将基础特征与领域特征送入深度学习模型,使用神经网络自动挖掘有用的组合特征。
由于色导用户识别与推荐任务中的点击率预测在建模中有着相似性,因此我们主要用到 xDeepFM、AutoInt 以及 DCN 这几个模型,但实验效果都未达到预期。
阈值选择
有了输入特征,有了模型,现在要训练使模型为每一个样本进行打分,打分结果接近于 1 的则更可能为色导用户。
那便存在这样一个问题,究竟打分结果高于多少时认定该样本为色导用户。
根据评估指标,我们的预测结果要权衡精准率以及召回率,因此,合适的分界可以更好的评估模型的优劣。
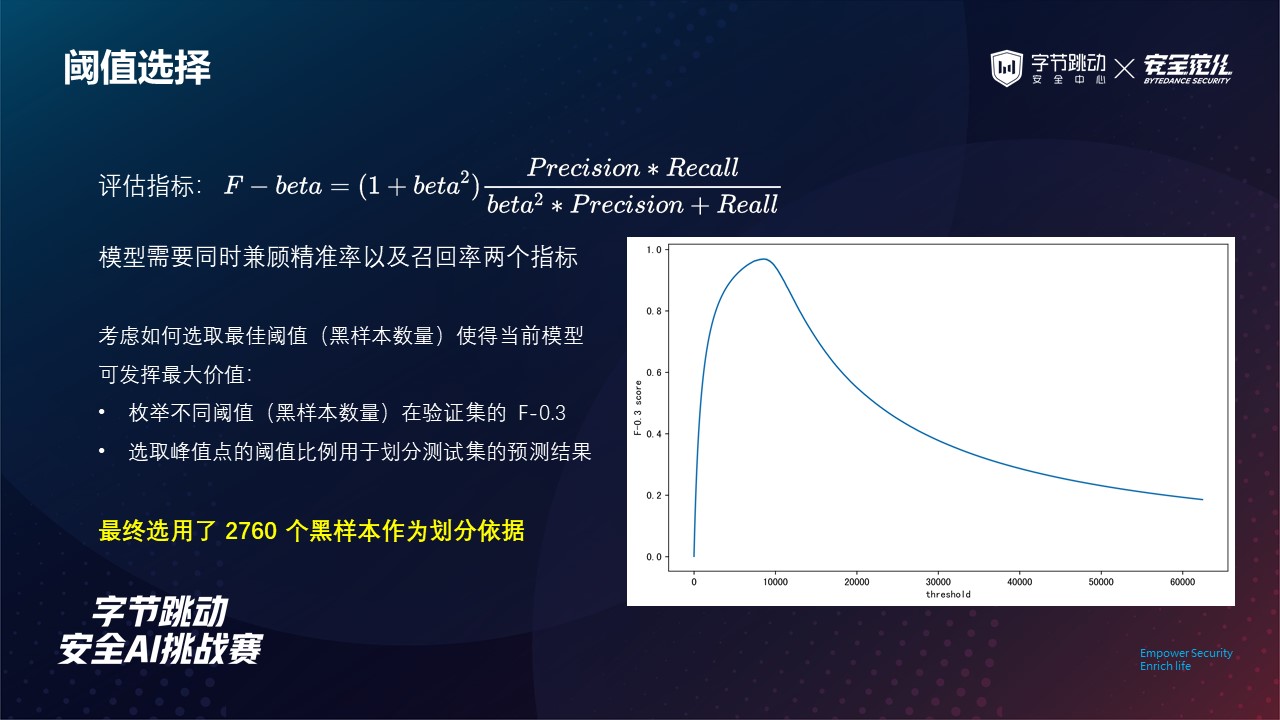
这里我们基于五折交叉验证中所有验证集的预测结果,按打分从高到低枚举不同的黑样本数量并绘制 F-0.3 的变化曲线,最后选取峰值点的阈值比例用于划分测试集的预测结果。
最终,我们的模型选用 2760 个黑样本作为划分依据(实际测试集黑样本数量应该是 3748)。
实验相关
其他尝试
除此以外,我们也做了许多其他的尝试,包括部分本地提升但在线评估效果降低的方案。

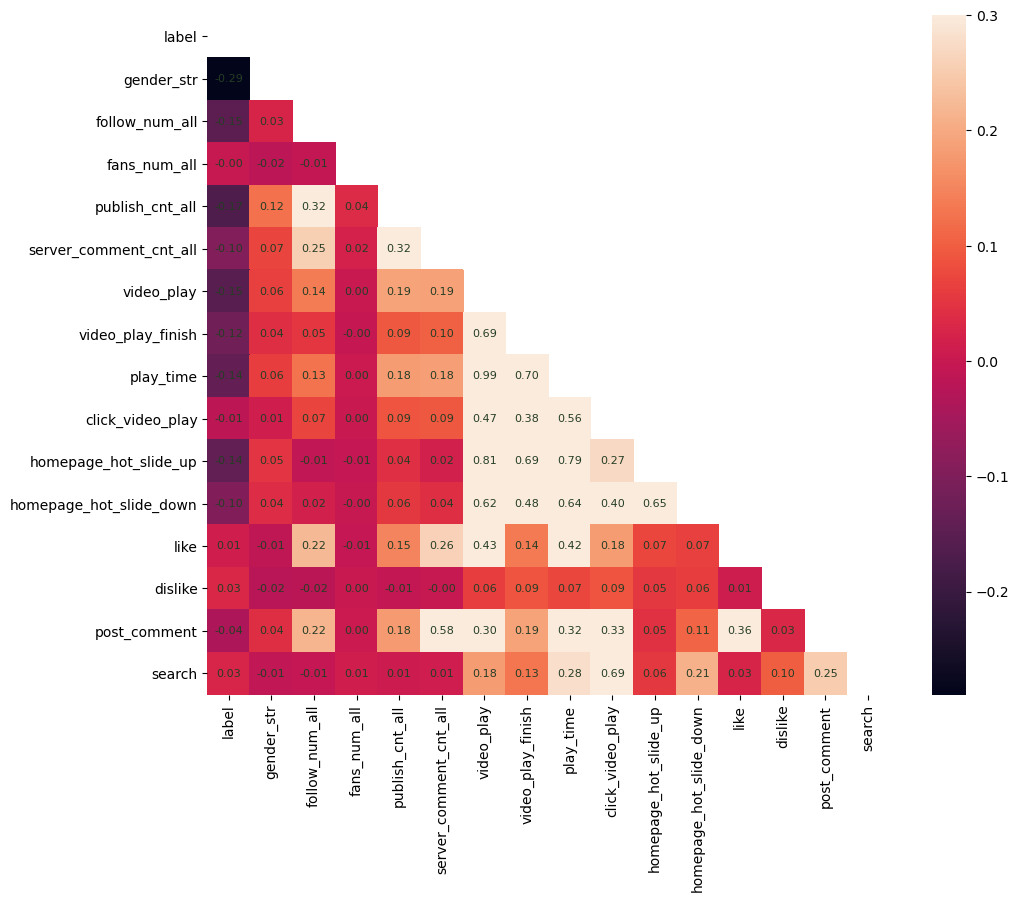
基础特征特征间相关性
基础特征经 catboost 训练后的特征重要性排行
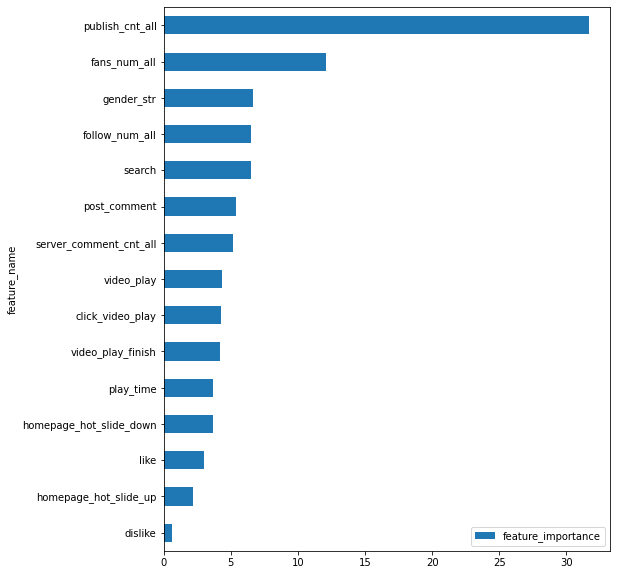
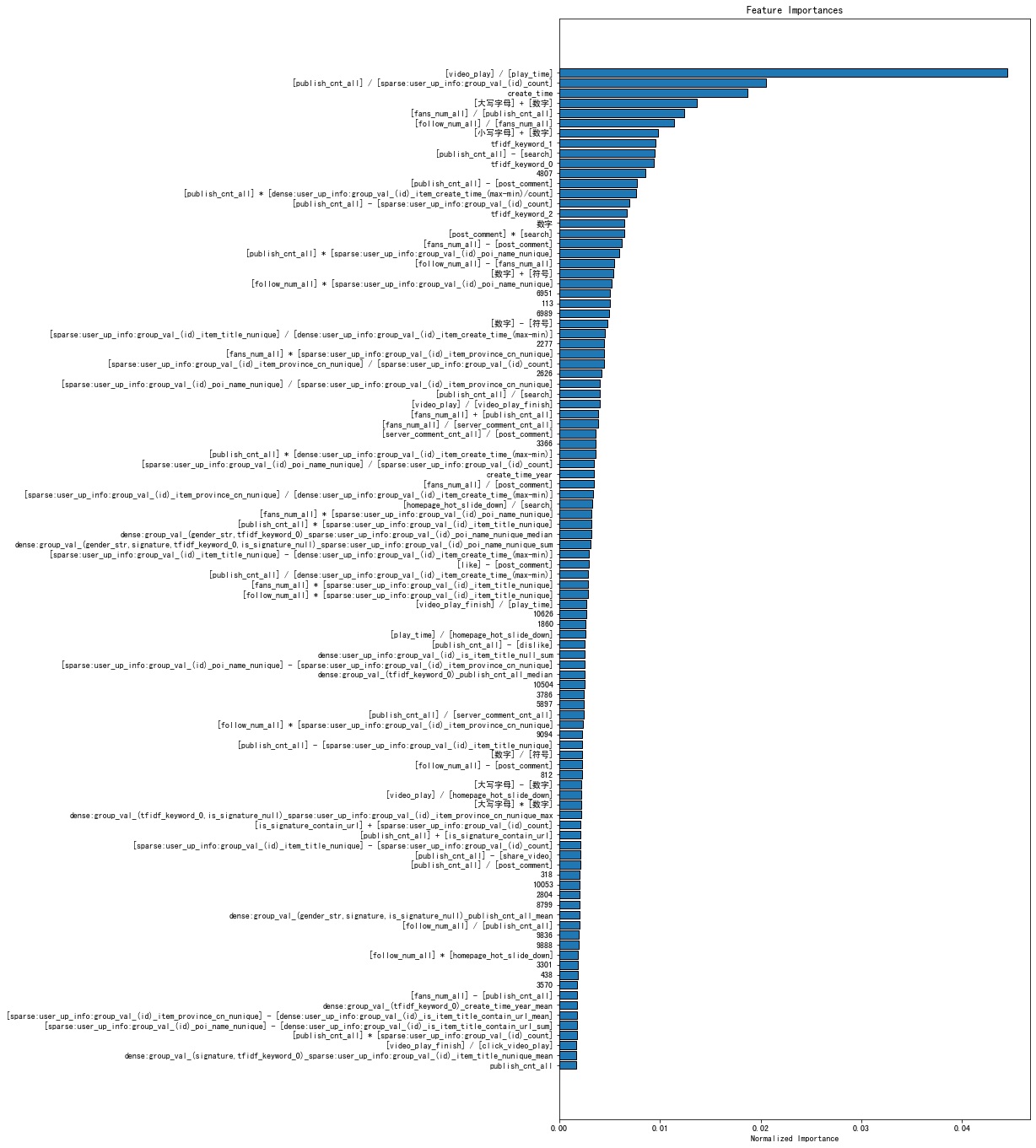
完整特征经 catboost 训练后的特征重要性排行
- 表中形如
A * B、A + B为对应特征的交叉 - 形如
4807、6951这样纯数字的特征为个签及视频标题的词袋表征对应 index 的重要性 - 形如
sparse:user_up_info_group_var_(id)_poi_name_nunique为针对用户上传表中的id列执行 group 操作,取 poi_name 列的 nunique 数作为特征;dense:开头的同理。
总结与反思
- 成绩永无止境,虽然我们的成绩在决赛队伍中处于垫底的水平,但重要的是在这次比赛中的收获。能够从前排队伍的分享中发现我们解决问题时的漏洞,才是最宝贵的。
- 要仔细对待特征中的异常情况,就像我们队发现了用户投稿时间训练集与测试集分布差异大,但这个特征却会让模型本地效果拉满。而我们做过尝试后觉得投稿时间这个特征很难迁移到测试集,于是便删除了时间大小相关的一部分,这大概也是我们与前面分数差异最大的一个原因。
- 最后,感谢主办方提供的这次学习的机会,受益匪浅!

QA 环节
Q1: 有没有分析过为什么深度学习模型相比于树模型效果要差一些?
- 关于这一点首先可以分析一下深度学习模型和树模型在学习的过程中更注重哪些因素。深度学习模型本质是感知模型,数据体现什么现象它就往哪边靠。但树模型是基于信息熵,哪一列特征更具区分度就优先划分哪一个。
-
在色导用户识别还有像推荐的一些任务里,正负样本以及长尾分布的现象是非常明显的,这对于深度学习模型来说就是噩梦,模型感知到大量的数据预测为某个标签时它就倾向于建模这些数据,从而导致长尾尾部的那些信息难以建模,这是此类任务对深度学习的难点。
-
但树模型因为是基于一种可量化的规则建模的,本身并不会受到类似的影响。
- 这是之前分析到的一些点,但也不排除我们深度学习模型写的有点拉跨导致的。
Q2: 有没有在特征重要性这块做过细致的分析,然后哪些特征更为重要,沿着这个方向深入挖掘?举例哪些是找到的,哪些是扩展出来的。
- 我们整个工作大体上是基于特征重要性来做的,例如发现某一个特征的重要性突然排到了前面,那便去分析这一个特征的 PSI 指标,判断特征在训练集与测试集上的一个稳定性,如果较为稳定,那我们会基于这一个特征进行一些组合、聚合或者是其他操作进行扩展。
- 例如对于个性签名,我们抽取了 TF-IDF 关键字,而关键字这一个特征排到了特征重要性表的前面,后面我们分析可能存在许多谐音字然后和正常的字组合形成短语语义,因此反脱敏出所有的字母数字还有符号,并把相关的一些统计特征也加入到了模型中。当然,也有许多其他类似的工作。
Q3: 从讲解中感觉在数据分析类的工作偏少一些,这部分是没有展示还是没有做?
- 关于数据分析我们是做过一些的
- 例如针对时间特征,我们分析到训练集与测试集之间的分布差异,并做过类似于小时级别的时间平移(主要为了避免因为 0-24 本身是一个环的特征被建模成连续特征而丢失一些信息),但这一点最后没有取得效果的提升。最后尝试过一些方法后感觉难以建模就丢弃了时间大小相关的那部分特征。
- 然后针对其他特征,我们也分析某些特征上的长尾现象明不明显,需不需要分段来建模该特征
- 此外,我们也根据训练集及测试集中各个特征的 PSI 指标,用来分析该特征是否稳定,预判加入某个特征是否容易使模型出现过拟合的现象
Q4: 有没有考虑模型鲁棒性的一些因素?
- 目前主要使用五折交叉验证,然后在五次训练的过程中对测试集的打分取平均,以此降低模型预测的 bias。
Q5: 一类导流方式是通过大规模的发布然后诱导用户产生关联,但是在本次工作的介绍中没有看到相关的关联关系,这个是什么原因,是因为本身提供数据的限制还是基于什么样的考虑?
- 是的,目前提供的数据没有相关的信息。
Q6: 有没有观察过一些误判的 case 是什么?这些误判的 case 主要是因为哪些特征导致的?
- 因为数据脱敏的原因,难以观察误判 case 的个性签名及其投稿的视频标题。
- 我们主要针对阈值附近的一些误判 case 做过分析,但除了序列特征以外的其他特征并没有发现异常,因此主要怀疑是个性签名或视频标题中有一些奇怪的点存在。



感觉这种表格数据还是树模型擅长一些hhh
我之前呆的地方从树模型迭代到深度模型都是因为需要加入其他需要NN处理的模态的强特征才迭代的。
想问一下 Top 队伍里面有使用有使用深度模型的嘛?
哈哈哈,不同场景有不同适合的解决方案。这次 top 队伍基本全是树模型搞的,我记得没有人用深度模型的 >﹏<
大佬,可以分享一下赛题数据吗
数据官方不允许传出来的,呜呜呜
哈哈,好吧
不过有源码,里面能看到一部分数据示例