
论文标题:Alleviating Cold-Start Problems in Recommendation through Pseudo-Labelling over Knowledge Graph
发表会议:WSDM 2021
论文链接:https://arxiv.org/pdf/2011.05061.pdf
要解决的问题
本文聚焦于缓解推荐中的冷启动问题。
试想一下,在推荐场景中,当客户想要投放新广告时,由于该广告从未被曝光过,导致召回阶段便可能排除了它,就不用再说后面粗排精排或者重排了。
一句话描述
作者针对冷启动问题,基于观测数据(user-item 交互)建图,然后从已观测 item 集合出发探索未观测的 item,伪样本采样正比于观测集合到未观测 item 的可达路径数,负样本采样正比于该 item 与 user 的交互次数,最后基于 co-training 的思想训练模型,输出为 (user, item, label) 这样的样本。
具体解法
定义
- user 集合:$\mathcal{U}$
- item 集合:$\mathcal{I}$
- $u$ 可观测到的 item 集合:$\mathcal{I}^{+}_u$
- $u$ 不可观测到的 item 集合:$\mathcal{I} \backslash \mathcal{I}^{+}_u$
- 正样本集:$\mathcal{I}^{+}_u$
- 负样本集:$\mathcal{I}^{-}_u$
- 伪样本集:$\mathcal{I}^{±}_u$
知识感知图神经网络
这部分作者使用 GNN(架构接近于 KGNN-LS)主要考虑节点特征可以在图上进行交互,以达到更好的伪标签生成效果。感觉也不是本文重点,想要了解的同学可以点进原文看一看。
基于伪标签的半监督学习
在推荐场景中,一个用户所能覆盖到的 item 量是非常少的,但未被覆盖的 item 并不能说它针对该用户一定是负样本。因此可以使模型去预测未被观测样本的 label,以此来缓解正样本稀疏的问题。
作者将数据拆为正样本、负样本与伪样本,正负样本的标签已然明了,需要模型去做的便是预测伪样本的标签,它可以暗指 item 与 user 之间产生交互的概率。
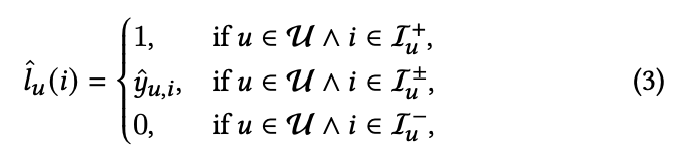
损失函数
实际就是正样本越靠近 1、负样本越靠近 0、伪样本越靠近伪标签。
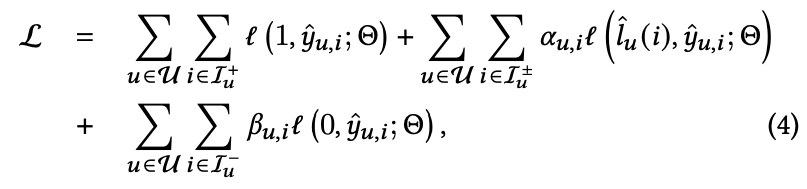
基于知识图谱的流行度采样
伪标签采样
在这一步中,作者使用 user-item 之间的观测数据建图,然后基于 h-hop BFS 检索正例集合以外的点,随后通过以下公式采样伪标签:
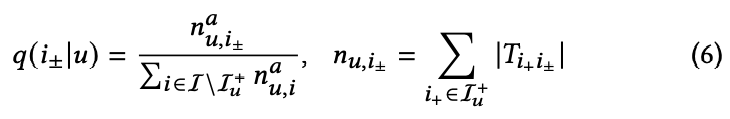
其中 $n_{u,i±}^a$ 代表针对 $u$ 有多少个正例可以在 $h$ 跳内与伪样本 $i±$ 可达,若已观测 item(正例)与未观测 item 间的可达路径数越多,则该样本的采样概率越大。
其中 $a$ 是一个可以控制采样分布偏向(skewness)的超参数,若 $a$ 越小,则采样越偏向于均匀分布。
负样本采样
作者考虑到冷启动的 item 本身相比于流行的 item,其更容易被采样为负样本。这一偏差会影响模型的效果,因此使用下式根据 item 的流行度抑制其被采样概率。即,越冷门的 item 越不容易被采样为负样本。
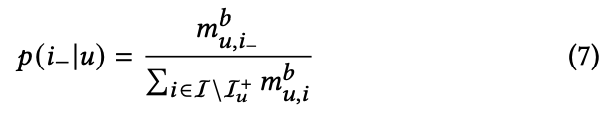
其中 $m^{b}_{u,i_-}$ 代表 $i_-$ 与 $u$ 的交互次数,而 $b$ 用于控制频次的重要程度(和伪标签采样中的 $a$ 相似)。
mini-batch 构造策略
伪代码如下,生成的样本中(正例、负例、伪标签)是均匀的。

co-training
在模型本身生成的伪标签上训练自己会让优化变得不稳定,因此作者同时训练了两个模型 $f$ 与 $g$ ,其中每个模型使用的伪标签都是由对方产生。逐步迭代,从而提高模型的鲁棒性。
训练过程
- 采样两个 mini-batch $B_f, B_g$,其伪标签分别由模型 $f, g$ 预测得到。
-
将 $B_f$ 输入 $g$ 训练,将 $B_g$ 输入 $f$ 训练。
多轮迭代完毕后,使用 $f$ 作为伪标签的生成模型。(这里想用 $f、g$ 的平均或 ensemble 等方式也都行)
损失函数
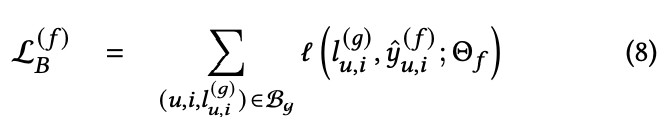
实验
作者在三个开源数据集 Movielens 1M、Last.FM、BookCrossing 中对比了一些基于 KG 的推荐算法。
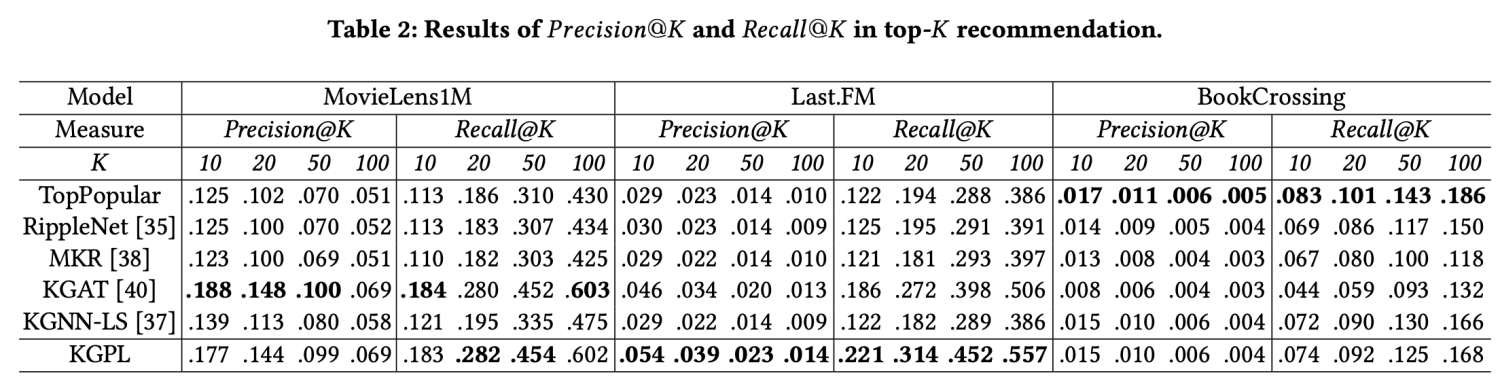
实验中模型的效果也是挺不错的。



赞一个
感谢感谢~ 欢迎常来哦~
论文…优秀的博主 现在能坚持写博文的博主不多了 赞一个!
感谢感谢~ 欢迎常来哦~
赞一个
感谢感谢!哈哈哈,欢迎常来呀~
感谢分享,赞一个
哈哈,欢迎常来呀~
果然技术文评论的少⌇●﹏●⌇
哈哈,也可能文章更新的慢,大家都不怎么来