
2333 千千也标题党一回,略略略~
太难了,昨天刚刚知道结果,随手发了一个朋友圈。
然后,就被辅导员抓去写稿子了,呜呜呜。😭
想着,既然好不容易写了一篇稿子,也在这里水一篇啦~
不过开心是真的~ 啦啦啦~😄
以下正文,大都以第三人称描述,当然也就不实名咯~
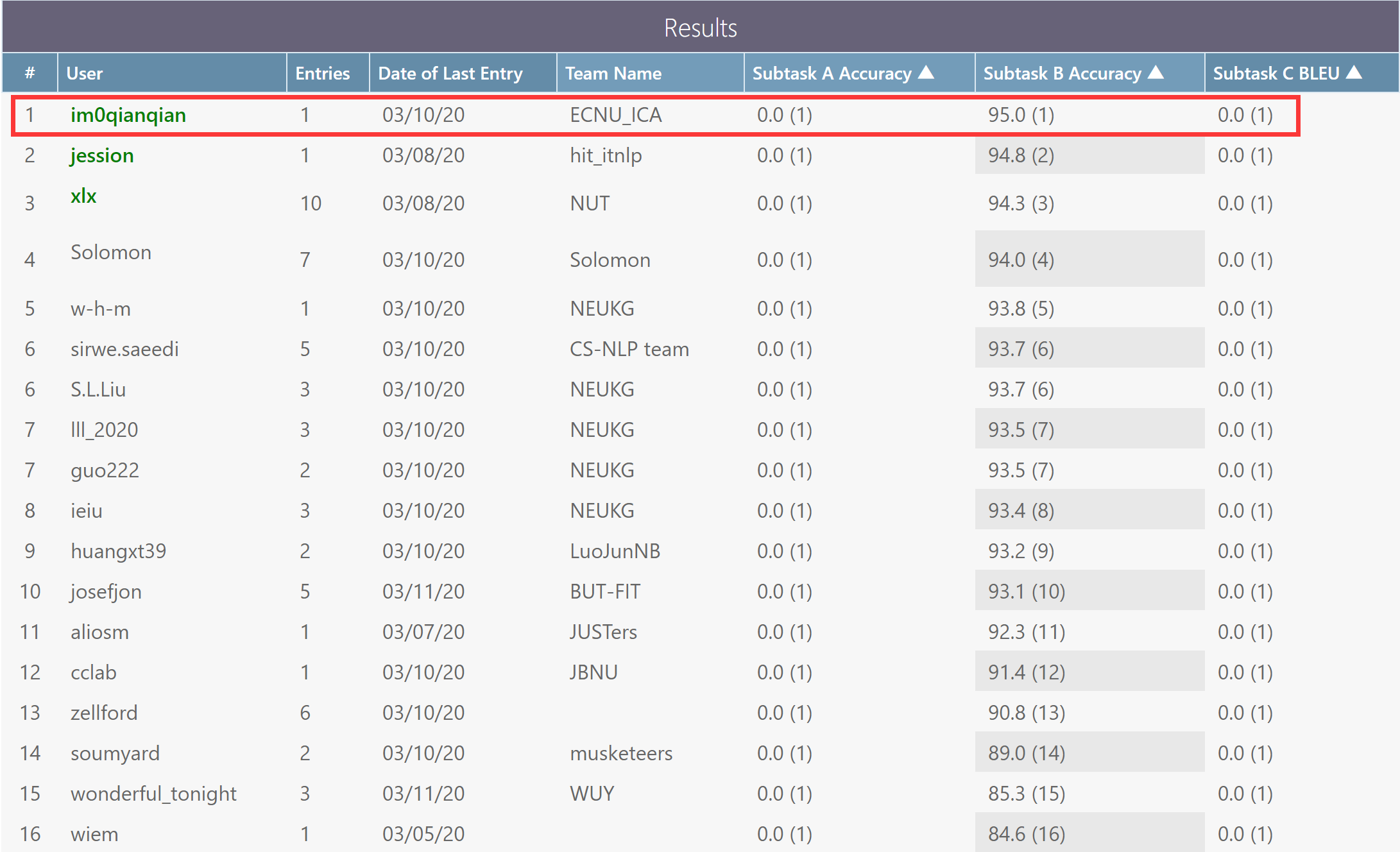
近期,第十四届国际语义评测大赛(International Workshop on Semantic Evaluation 2020, SemEval 2020)落下帷幕。在 Task 4: Commonsense Validation and Explanation 常识验证与解释评测任务中,由我院 ICA 研究所的(我导师 + 联合培养的另一位老师)担任指导老师,千千、小雨等同学组成的参赛队成功获得子任务 B 第一名,子任务 A 第二名,撒花~ (●ˇ∀ˇ●)。本届比赛也吸引了包括哈尔滨工业大学、香港中文大学、雷丁大学等著名全球高校。

这是一项什么样的比赛?
SemEval 是全球范围内影响力最强、规模最大、参赛人数最多的语义评测竞赛,由国际计算语言学协会(Association for Computational Linguistics, ACL)下属的 SIGLEX 主办。ACL 作为世界上影响力最大、最具活力的国际学术组织,其举办的计算语言学年会(Annual Meeting of the Association for Computational Linguistics)是国际自然语言处理的顶级会议。自 2001 年起,SemEval 至今已成功举办了十三届,吸引了世界范围内的多所大学和研究机构的参加,在业界和学术界具有极高的影响力。根据 Google Scholar 的数据,发表在 SemEval 的文章在 Computational Linguistics 领域的影响力仅次于 ACL/EMNLP/NAACL 三大顶会,位于 NLP 会议、期刊中的第四位。
比赛的任务主要是做什么?
本次评测聚焦的任务是常识验证与解释(Task 4: Commonsense Validation and Explanation),旨在从包含反常识的文本中推断出它为什么反常识,并做出合理的解释。
Task 4 一共包含三个子任务,分别是
- Subtask A. Commonsense Validation
- Subtask B. Commonsense Explanation (Multi-Choice)
- Subtask C. Commonsense Explanation (Generation)
其中 Subtask A(Commonsense Validation)给出两句拥有相似结构的陈述,任务是检验哪句陈述相对符合常识,哪句不符合常识。例如:『A: He put a turkey into the fridge』对比『B: He put an elephant into the fridge』。显然,大象不可能被放进冰箱,这是反常识的,因此正确答案:A 相对符合,B 相对不符合。
Subtask B(Commonsense Explanation Multi-Choice)是从 Subtask A 承接而来,给定一句不符合常识的陈述,并给出三个候选原因,选出最能够解释该陈述之所以反常识的原因。例如不符合常识的陈述为:『He put an elephant into the fridge』,三个候选原因分别是:『A: an elephant is much bigger than a fridge』、『B: elephants are usually gray while fridges are usually white』、『C: an elephant cannot eat a fridge』,正确答案为 A。
Subtask C(Commonsense Explanation Generation)也是从 Subtask A 承接而来。给出不符合常识的陈述,并要求生成解释其不符合常识的原因。相比于 Subtask B,从 Multi-Choice 变为了 Generation,这也为该子任务增加了一定的难度。其结果以 BLEU 值来衡量,最终结果会以人工评价的方法进行衡量。
任务的难点与挑战体现在哪儿?
本次任务较多的涉及到常识(Commonsense),而常识的欠缺是如今限制自然语言处理领域乃至其他领域进步的一大瓶颈,许许多多的学者曾经为此做过大量的工作,但取得的成效却微乎其微。
即使近些年来预训练语言模型(Pretrained Language Model)的兴起为 NLP 领域带来了新的曙光,很多榜单也被这些模型统统刷了一遍。但是,面对常识问题时,预训练语言模型的效果并没有想象中的那么好。众所周知,现有的预训练语言模型(如 Bert、GPT-2 等)大都基于大量的文本以自监督的方式训练起来的,但恰恰不巧的是,多数情况下,常识并不会显式的包含在语料中,常识是作为一种基础性的知识隐含在说话人的脑中,这是人人所拥有的,即使不说对方也应该了解的知识。正因为如此,常识知识或许并未被预训练语言模型所学习到,从而也限制了其发挥。
关于参赛 & 队员想说的话
在本次评测任务中,我们队伍充分思考了当前常识知识难以被模型所学习的问题,并采取多种技术手段,最终巧妙的将有用的常识信息成功注入到预训练语言模型中,从而取得了亮眼的成果。结果显示,我们的方法在两个子任务中均表现出较好的成绩,尤其在难度更高的 Subtask B 中取得了榜首第一名(准确率 95.0%)的好成绩。
千千:这几个月以来,整个团队每天探索好的 idea、激发新的灵感深入讨论、攻克难题的努力没有白费,最终取得这样的好成绩也是比较开心的。期间与队友前去复旦参加肖仰华教授所邀请举办的常识研讨会,收获也是满满的。非常感谢各位老师和师兄的指导,也感谢队友和同学的鼓励。比赛的帷幕终于落下了,也激励我向更高的目标继续钻研,希望一切顺利。
小雨:在老师们的指导和同学们的努力下,这次我们小组在 SemEval 2020 大赛的 Task 4 任务上取得了比较不错的成绩。现在想起来,在比赛刚开始的时候,我还是一个刚刚步入自然语言处理领域的新人,一开始就参加这种在 NLP 领域非常著名的国际竞赛,心里还是非常有压力的,担心自己的水平不能够胜任这样的任务。在进行竞赛的那段时间里,碰到了很多困难,也曾因为实验的效果不好而犯愁,但最终在老师和同学的共同努力下,我们克服了碰到的问题,并且在实验的效果上也取得了很大的提升。非常感谢老师给了我们这次参加竞赛的机会,也很感谢小组成员们的支持和鼓励。
讲真,感觉一大部分还是运气的成分😣
Commonsense 这块东西太难搞了,浅显一点的还行,想要深入不好做 QAQ
千千在前面的一篇文章中也提到过了,那么多大佬都没什么可以跨越性提高到 idea
害怕-ing >︿<
接下来要开始肝 SemEval 4.17 的 DDL 了,希望一切顺利吖~
也希望其他的任务也顺利起来~ (っ °Д °;)っ



真是羡慕读书的大佬们,不用为了生活发愁
读书的,也在为导师的任务还有毕不了业而发愁 QAQ
%%千神~
小坏蛋千千开始标题震惊营销文了 (逃 ~
平均震惊率不到 1%,还可以接受吖~ 嘻嘻~ |´・ω・)ノ
文章还不错支持一下
感谢支持~
膜拜大佬
还是运气好