Hello,大家好,今天主要给大家介绍的是融合知识的预训练语言模型。
我会从这一 topic 的研究动机、所存在的挑战、以及目前几类模型的优缺点来一一分享。
如有不足,欢迎指正。
PPT 链接:PLMs with Knowledge
预训练语言模型的分类
我们将预训练语言模型分为两类,一类是 Feature-based Pre-training model,另一类是 Finetuing-based Pre-training model。
在 Feature-based PLMs,这里主要介绍一个 ELMo。在 ELMo 出现以前,词向量这个概念被广泛应用在各个场景。比较常见的有 Word2vec、GloVe 等,但这类的词向量信息单一,一个词只由一个词向量表示,因为同一个词在不同情境下可能有着不同的含义,所以这种方法有着很大的局限性。比如单词 bank 既可以指银行,也可以指岸边。部分场景下单一词向量的方法也会带来很大的问题,比如引发歧义等。
ELMo 的核心思路是用大规模语料训练双向语言模型,得到能根据上下文语境变换而改变的词向量,这里的双向是指先训练一个从左到右,再训练一个从右到左的,然后将两者拼起来形成最终的词向量表示。这种表示融合了上下文信息,其表达能力相比于 Word2vec 等大大增强了。

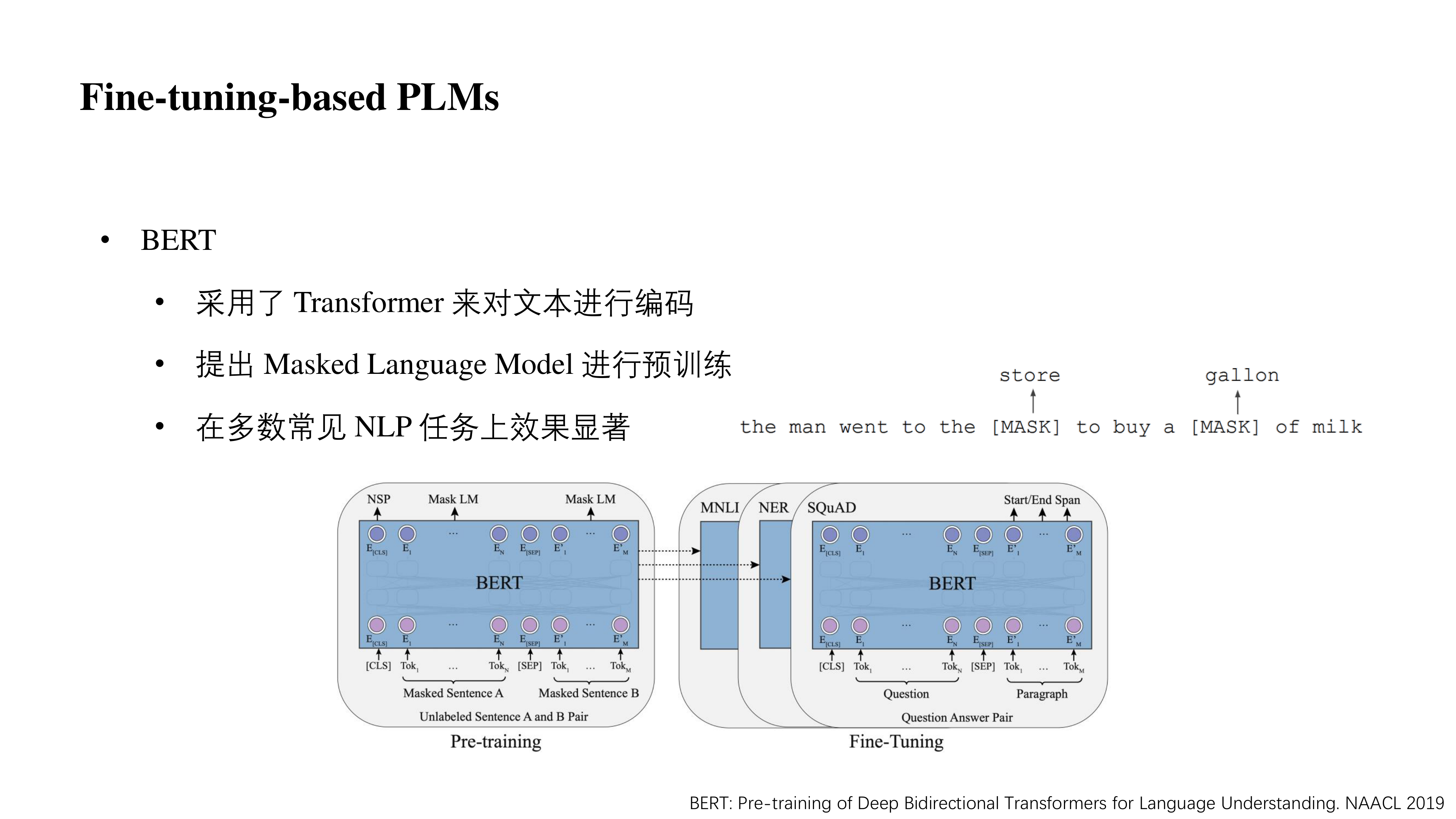
相比于 ELMo 双向 LSTM 拼接的方法,BERT 采用 transformer 编码器,其天生是一个双向语言模型,且其层数可以叠的很深,因此 BERT 的表达能力远高于 ELMo。
在 BERT 这种 Fine-tuning-based PLMs 中,其大致思想是使用大量的语料去无监督训练模型,使得模型可以学习到一个较为通用的词法、句法乃至文本中的语义等信息。然后再根据下游任务进行微调,从而使得网络在原始通用领域知识的基础上学到一些特定领域知识。实验证明即使单纯这样做,BERT 也可以在很多 NLP 任务中取得十分显著的效果。
在 BERT 预训练任务中,除了 NSP(Next Sentence Prediction,判断两个句子是否是相邻两句话)任务以外,作者还引入了 MLM(Mask Language Model)任务进行训练,即根据周边信息预测被 Mask 掉的单词是哪一个(如图中例子里的 store 与 gallon)。
前面说 BERT 天生是一个真正的双向语言模型,是因为它在预测每一个 [MASK] 时可以一次看到上下文,而不是像 ELMo 一样一次只能看到上文或者下文然后单纯的拼接起来。
预训练语言模型的发展
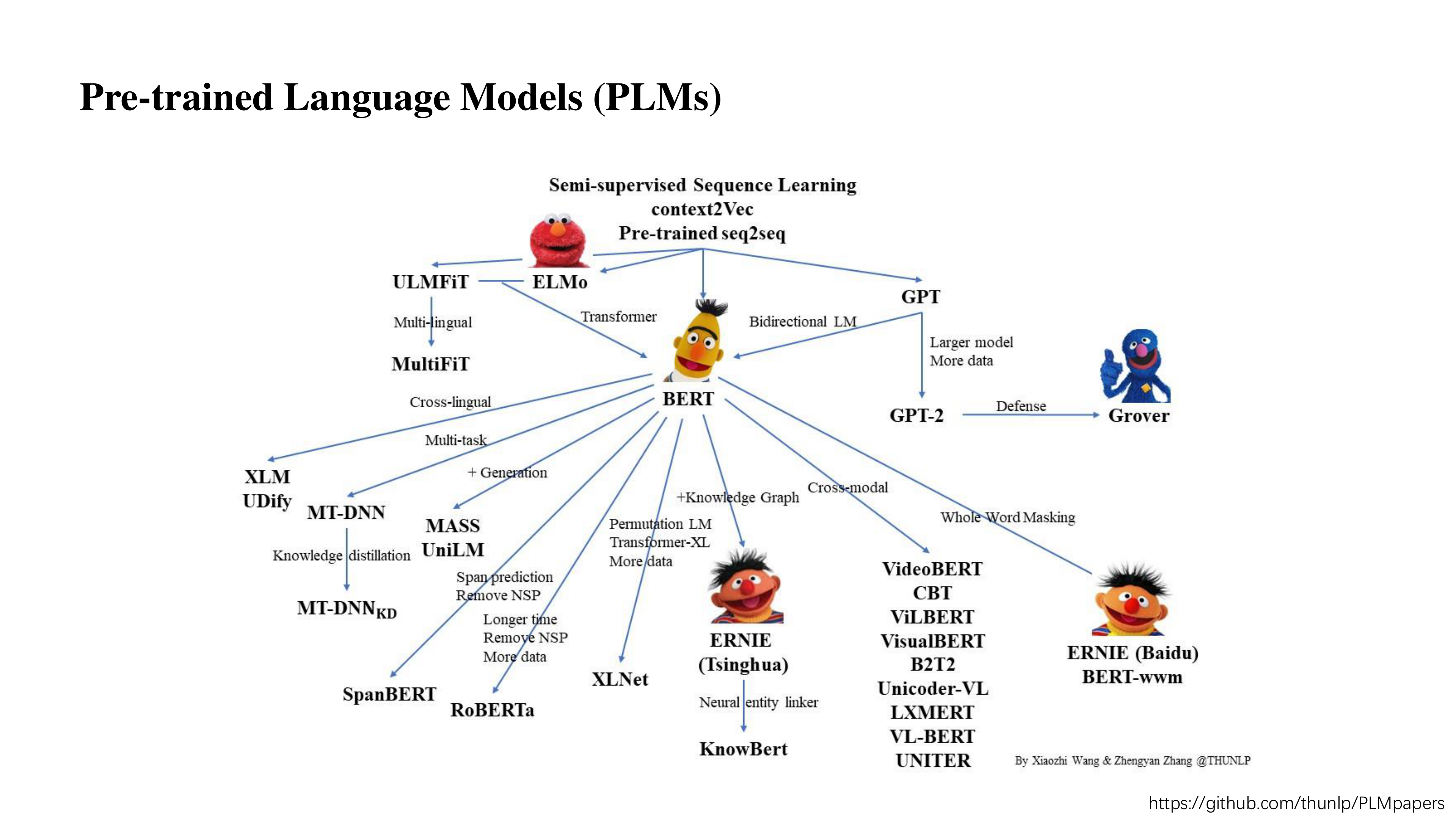
关于预训练语言模型,最开始的工作比如像 context2Vec、Pre-trained seq2seq,后来受它们启发产生了 ELMo、BERT、GPT 等模型。
当然,近两年最具有启发意义的工作还算 BERT,在 BERT 发布以后,出现了各种预训练语言模型的分支。比如像多语言的 XLM、UDify;引入多任务的 MT-DNN;或者是在 BERT 基础上改进了它的生成效果(BERT 本身不善于做生成,更善于做理解)的 MASS、UniLM;还有像用了更大的数据去训练的 RoBERTa;又或者是加入了外部知识的 ERNIE (THU)、KnowBERT 等。
链接在图片的右下角,感兴趣的可以去了解了解。
融合知识的预训练语言模型

嗯~ 要开始正文了,首先简单介绍一下融合知识预训练语言模型的研究动机。
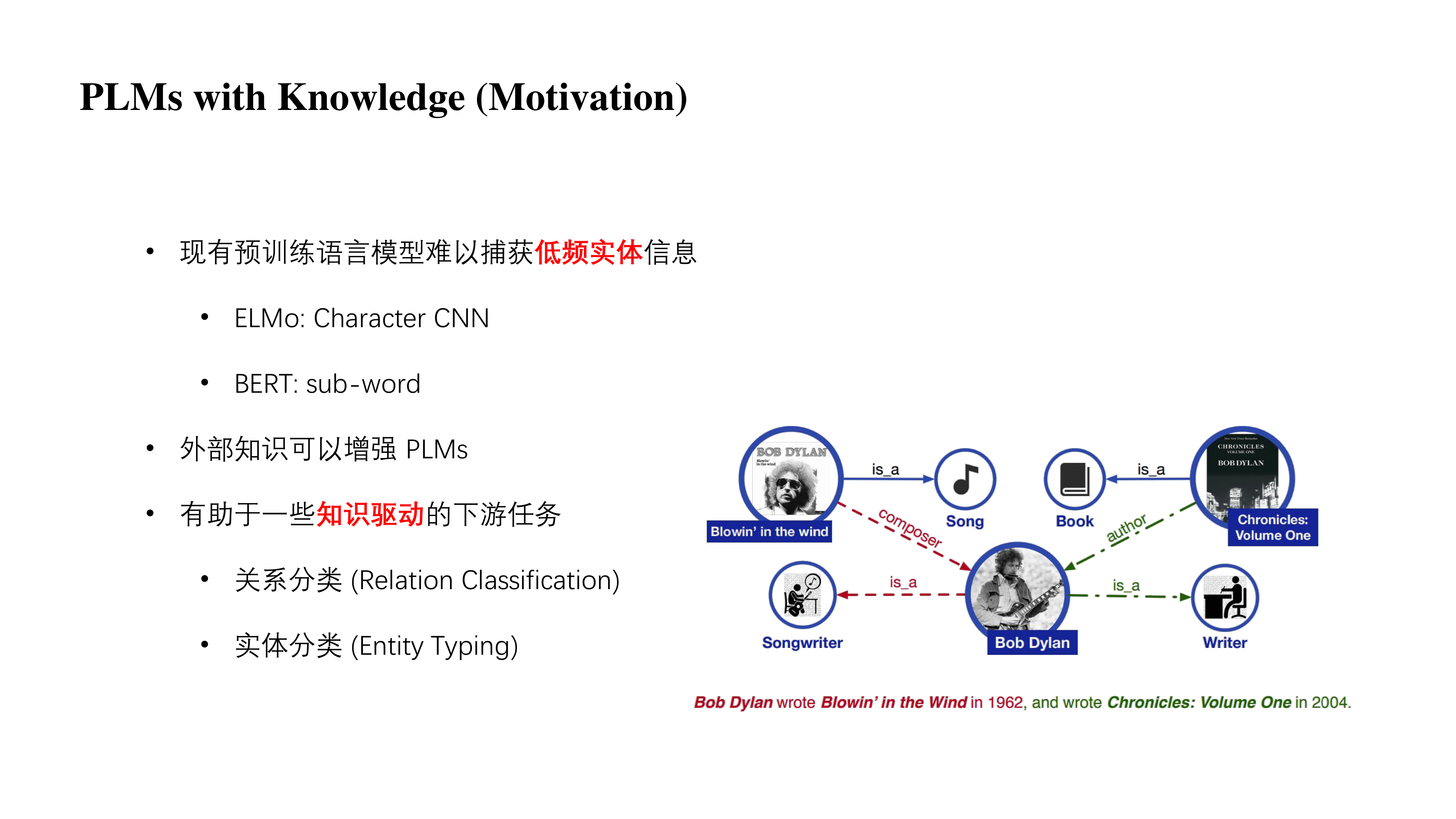
- 现有预训练语言模型难以捕获低频实体的信息,原因是它输入的时候就没有将实体的词组或者单词体现出来,比如像 ELMo 用的是一个单词级别的 CNN(一个单词会被拆成字母再分析),BERT 用的是一个 sub-word(一个单词可能会被拆成多个 token)。这些都是不利于模型去捕获低频的实体信息的,毕竟一个实体词组或者单词被拆了可能就看不出什么了。
- 考虑到引入外部知识其实是可以很好的增强预训练语言模型。
- 因此可以去帮助一些知识驱动的下游任务,比如关系分类、实体分类。
举个例子,如图所示,Bob 在 1962 年写了这首歌,2004 年写了这本书。在这两个『写』中实际上代表的含义是不一样的,模型目前是捕获不到这些实体的信息,但我们知道第一个是写歌、第二个是写书。因此在知识驱动的下游任务中,比如关系分类我们知道这首歌是他作曲的,知道他是这本书的作者。而在实体分类中我们又可以知道 Bob 是一个作曲家,也是一个作家。
但在做这项工作时实际上是存在一些挑战的,第一个是结构化知识表示,我们要根据文本从知识图谱中检索相关知识,并将其表示为低维向量。这实际上是一件很有挑战的事情,因为文本它是一个很典型的非结构化信息,而图谱是一个典型的结构化信息。如何很好的表示结构化知识帮助文本理解是工作中的第一个挑战。
第二个挑战是如何很好的将来自自然语言以及知识图谱的信息融合起来。原先的预训练语言模型会考虑到句子的词法、句法以及语义等一些信息,而外部知识中则会存在实体以及关系等信息。如何将这些多样化的信息融合起来以理解任务也是一项挑战。

ENIRE
知识图谱作为一个重要的外部知识来源,它可以提供很丰富的知识信息。
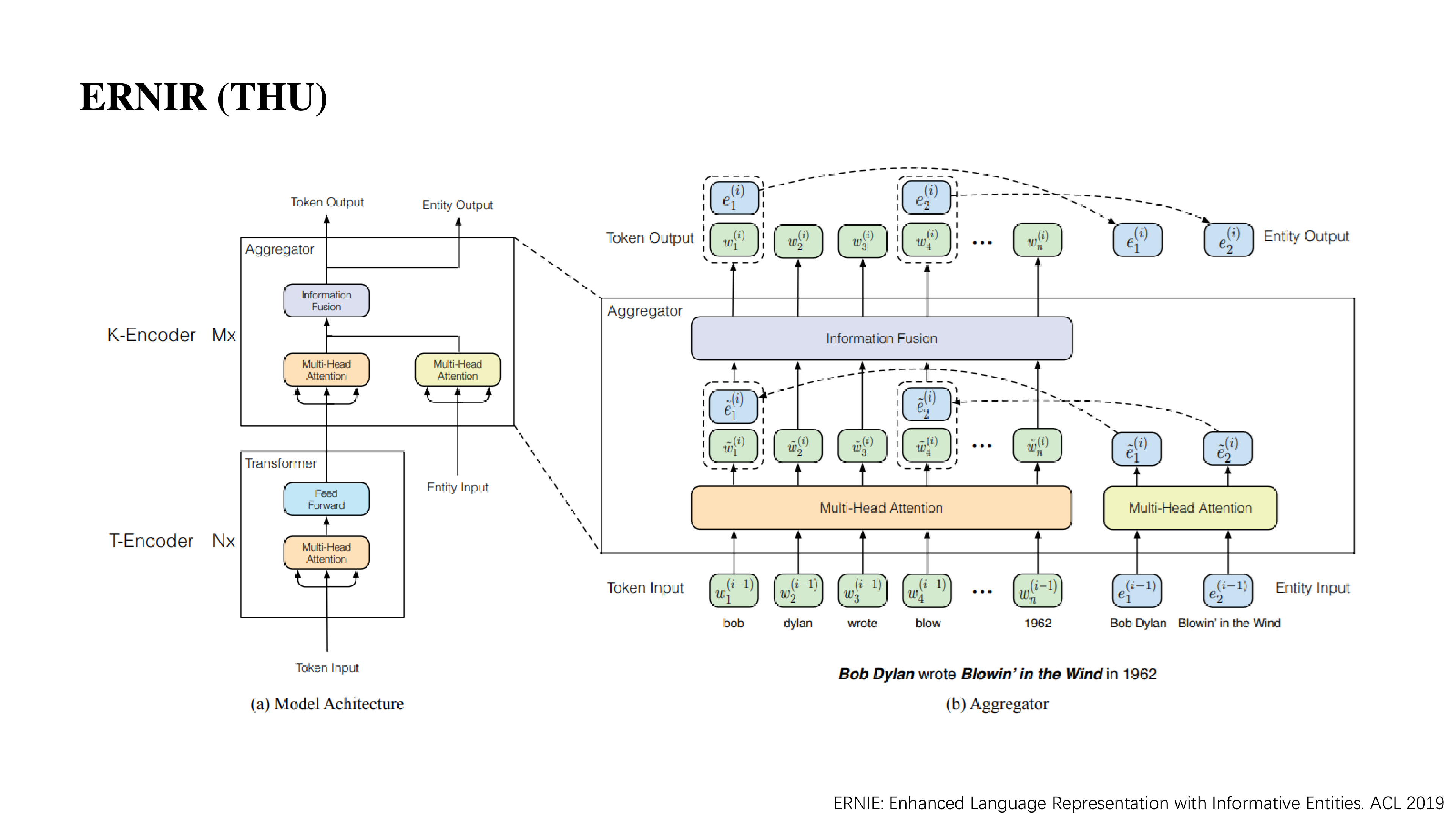
ERNIE 就是一个在大规模语料和知识图谱上预训练的语言表示模型,它其实是基于 BERT / transformer 模型做了一些改动。
主要分为两部分,第一部分 T-Encoder 和 transformer 没有区别,这部分主要做一个基本的文本信息建模。第二部分在高层中考虑如何把知识信息整合进去,这部分命名为 K-Encoder。K-Encoder 除了接受前面的文本信息以外,它还接受来自知识图谱的信息,之后经过一个信息融合的结构,使得实体信息能够注入到单词的表示中。
这里最关键的是如何进行信息融合,ENIRE 的做法是:
- 在开始时有一个待编码的句子。
- 利用实体链接技术将句子中的实体找到它在 wikidata 中对应的实体,有的多个 token 默认与第一个 token 对齐。entity input 是从图谱中学到的向量,token input 是从 T-encoder 学到的表示。
- 分别过一个 multi-head attention 做一次信息交互。
- 信息融合部分,分为两种情况,第一种是有实体的,第二种是没有实体的。对于有实体的 token 会将文本的 token input 与 entity input 拼接起来,然后过一层 Linear 形成一个中间结果,再通过两个不同的 Linear 得到下一层输入中的 token input 与 entity input;而对于没有实体的 token 则简单的过两层 Linear 得到下一层输入中的 token input。
- 反复进行。
ENIRE 最终的预训练任务在 MLM 基础上增加了预测被 Mask 的 entity。
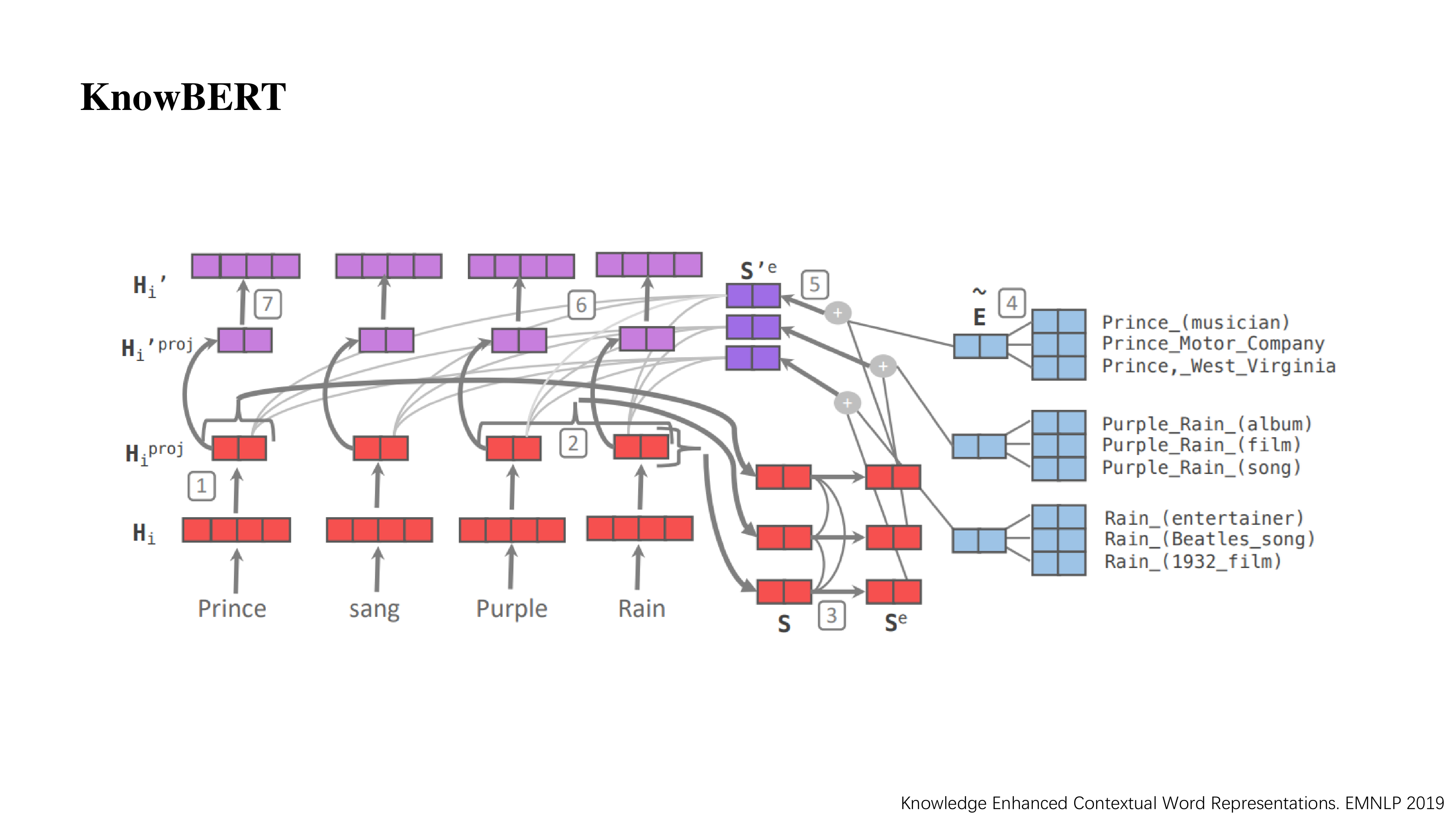
KnowBERT
这一篇 KnowBERT 本质上和 ENRIE (THU) 很像,如图所示,这里有 1 – 7 七个步骤。
- 对于给定的词向量先做一次编码,可能是 self-attention 或者 MLP。
- 对于 entity 所在的词向量进行合并,同一个实体向量可能由多个词向量合并而来。
- 实体间做 self-attention。
- 蓝色部分是从知识图谱当中学到的一些特征(实体向量 E),这里会得到相应的几个实体的特征向量。
- 文本中的实体信息与图谱的信息进行融合,得到紫色向量 S’。
- 原来的词向量和新生成的 S’ 做 self-attention,相当于知识注入的过程,把实体信息注入到文本中。
- 最后做一个 self-attention 或者 MLP 还原回最终的向量。
以上的两种方法看似巧妙,但使用训练好的图谱表示作为输入存在着一些问题:
- 图谱表示空间难以和语言表示空间融合,原因是图谱表示是一个典型的结构化数据中学出来的分布,而语言表示又是一个非结构化数据中学到的分布。两个差异较大的分布之间融合是很具有挑战性的。像 ERINE 中的 aggregator,KnowBERT 中的融合都是在做这样一件事。
- 另外一个是这项工作需要用到实体链接工具,它不可避免的会带来一些额外开销以及可能产生的链接错误。比如一些实体无法找到,或者对应不上之类的,而在使用中则会出现一些错误累积的现象,从而影响模型效果。
那如何摆脱图谱表示向量的束缚将知识注入到 PLMs 中呢?接下来我会介绍两项相关的工作。

KEPLER
第一个是 KEPLER,它主要是考虑使用统一的框架学习文本的表示和图谱的表示。
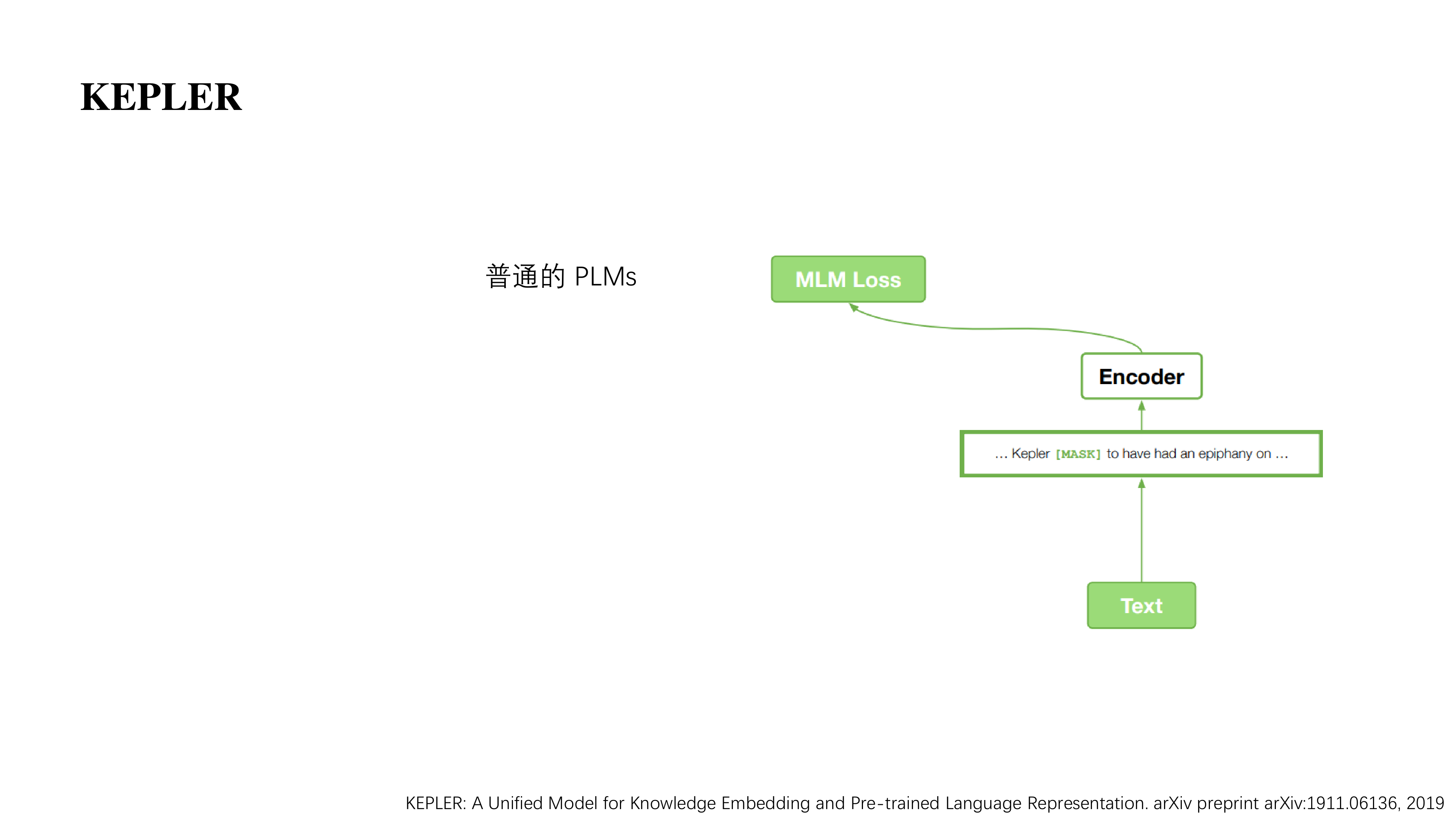
首先我们看看普通的 PLMs 怎么做的,初始时有一个很大的语料库,然后我们会将其中的一些单词替换为 [MASK],我们需要模型将 [MASK] 可以还原出来。它有个一个对应的 loss function。
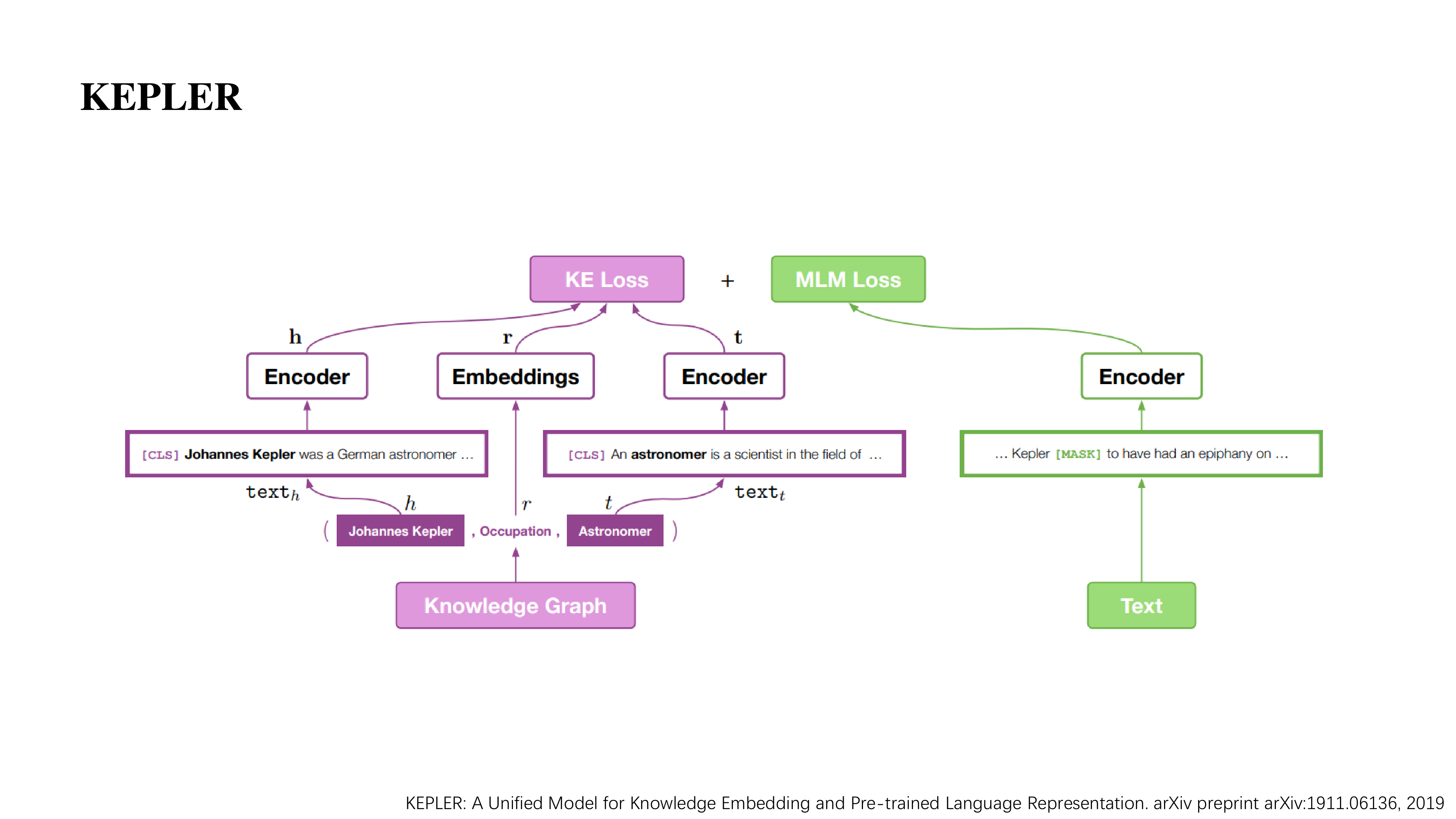
而 KEPLER 在这个 Mask Language Model 以外又引入了一个图谱表示学习的预训练任务。
在这个预训练任务中,由于 encoder 也直接参与了图谱表示的学习,因此它能比较好的将图谱知识融合到模型当中,既学到了图谱信息也学到了文本信息。
图中的左边其实是,对于给定的一个图谱,存在很多三元组 (h, r, t),而在该图谱中对于实体都有一些简单的介绍,这里作者就将这个介绍的表示作为实体的表示,然后再配上关系的表示向量。在设计 loss 时实际上可以有很多种,作者采用了 transE 的方法,也就是去优化 h + r = t 这个目标。
这样就相当于将预训练语言模型参与到图谱表示的学习,它就可以让模型既学习图谱,也学习文本的信息。
WKLM
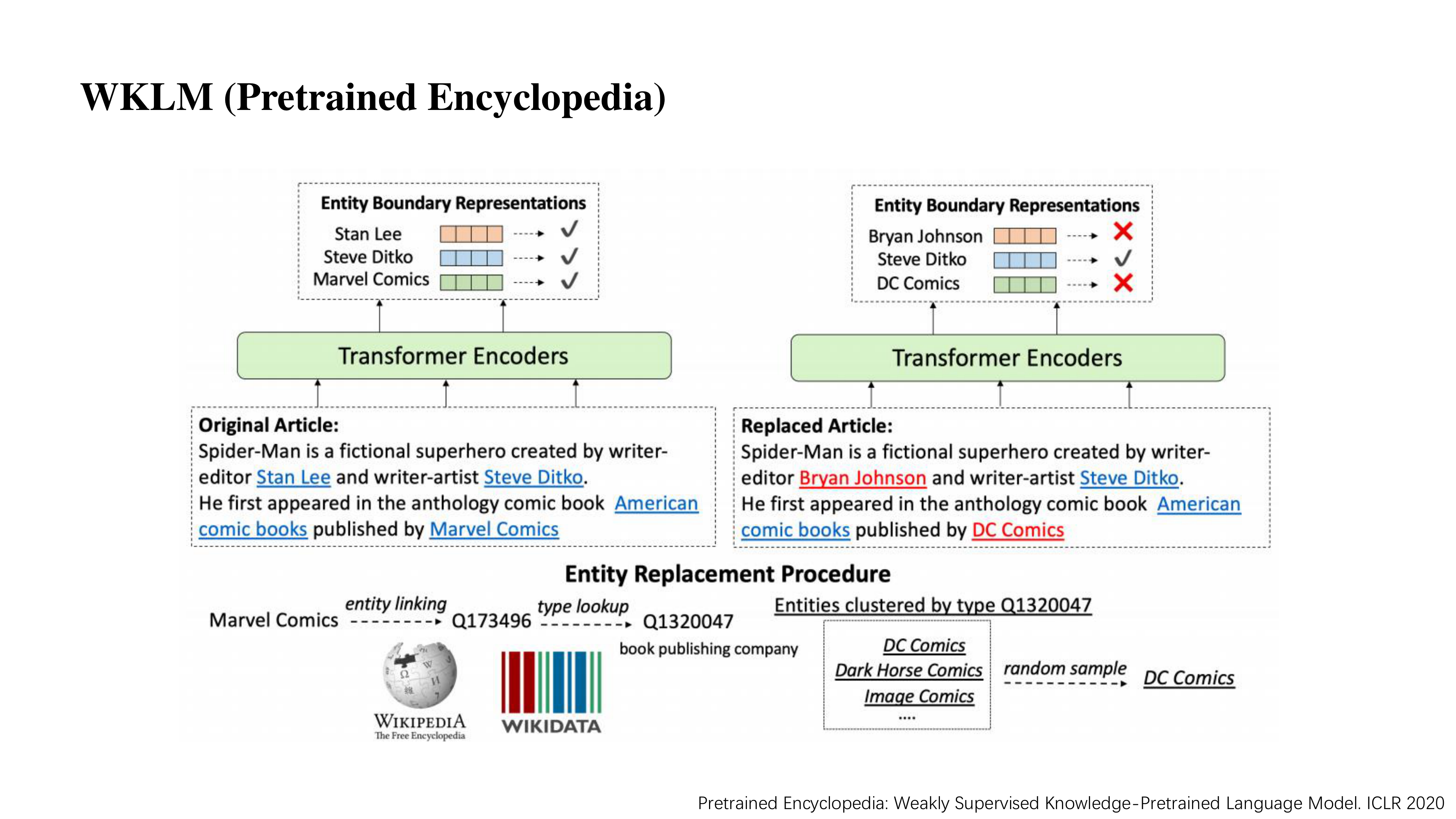
这一篇 WKLM 发表在 ICLR 2020 中,思路与 ELECTRA 比较类似。
下面简单介绍一下其思路,如图所示,举个例子。
我们对每一句话做 entity linking,找到了五个实体,然后对这五个实体进行一定概率的替换,那被替换掉的实体也便是问题实体。
然后让模型去判断这些位置的实体是否有问题。这样就间接的让模型去更加注重实体的学习。
它不需要引入额外的参数,也不需要在下游任务中做一些处理。WKLM 在预训练的过程中就已经学好了实体。
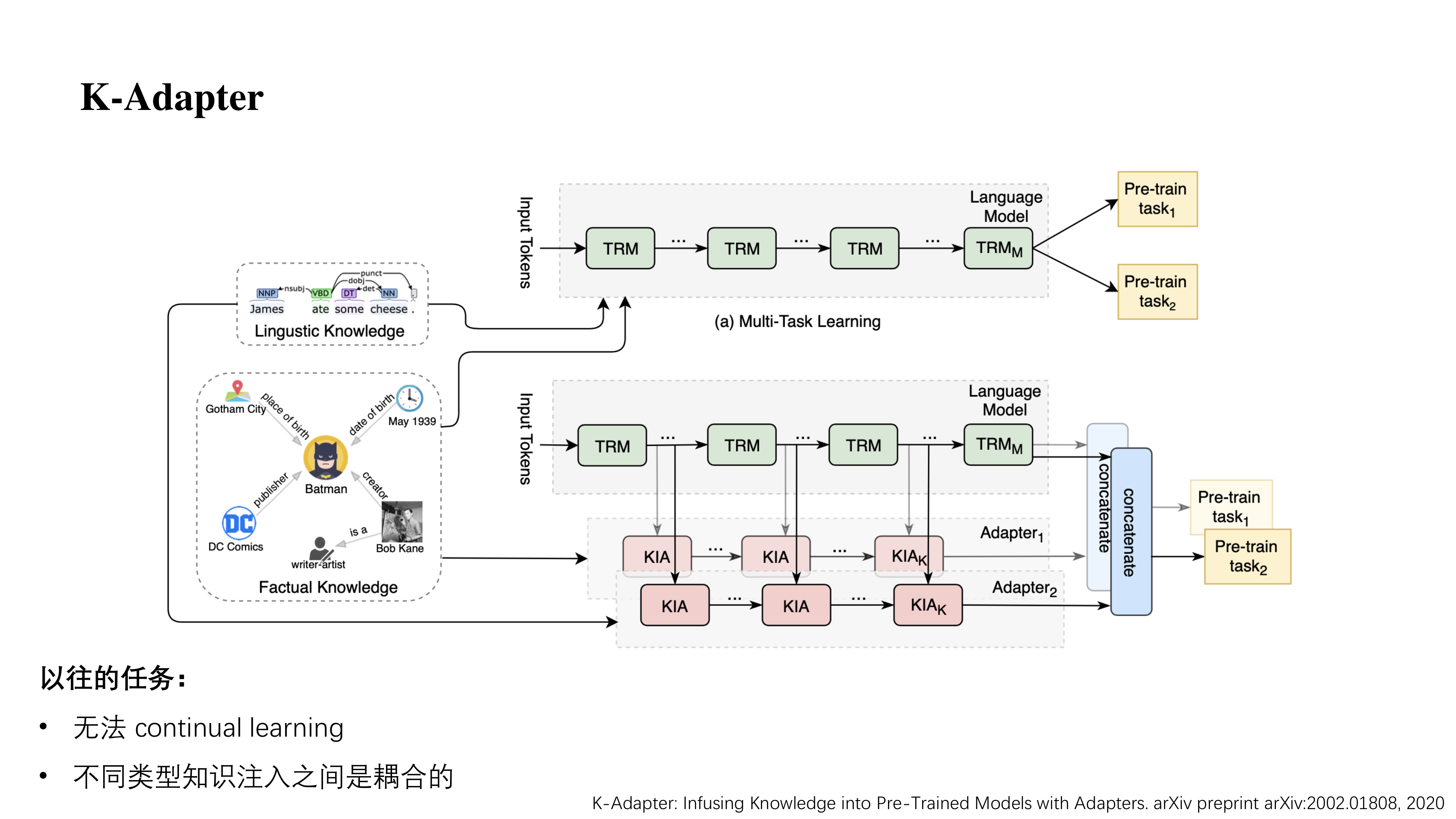
K-Adapter
最后的这篇 K-Adapter,它考虑的是当我们有一个很好的预训练模型,我们想要在它上面增加新的知识。
以往的工作大都需要做一个额外的训练,然后额外训练的过程中可能会导致一些灾难性遗忘。比如在学习新知识的时候会忘掉原来学到的内容,这样在一定程度上可能减弱了预训练语言模型的能力。
K-Adapter 它选择保留原先 PLMs 的参数,然后新增加一个模块 Adapter,在新的训练任务中只训练 Adapter。这里的 Adapter 类似于一个插件插在 transformer 的各个层中间。
这样既可以学到新的知识,又不会遗忘原先预训练语言模型学到的。并且想要多种领域的知识时只需要将几个 Adapter 组合在一起。
(作者也提到,Adapter 所学到的知识可能和 PLMs 中有一部分是重叠的,如何让 Adapter 做出更大的贡献也是一个可研究的点)




踩踩
欢迎常来哦~
很专业的资料
文章写的很好啊,赞(ㆆᴗㆆ),每日打卡~~
哈哈,感谢感谢~
又发现一个好站,收藏了~以后会经常光顾的୧(๑•̀⌄•́๑)૭
哈哈,欢迎常来哦~