前言:
在写这篇文章之前,首先感谢给我思路以及帮助过我的学长们
以下4篇博客都是学长原创,其中有很多有用的,值得学习的东西,希望能够帮到大家!
1、手把手教你用C++ 写ACM自动刷题神器(冲入HDU首页)
2、 [C#] 逆袭——自制日刷千题的AC自动机攻克HDU OJ
3、C#利用POST实现杭电oj的AC自动机器人,AC率高达50%~~
4、继续Node爬虫 — 百行代码自制自动AC机器人日解千题攻占HDOJ
当初抱着想试试的想法,用过他们的程序,嗯~ o(* ̄▽ ̄*)o。
1、比如那个用C++写AC机的学长,他的程序是用VS2013编译的,原谅我的C++并不是学的很好,照着他的教程试过好多次也没有运行成功,最终只能以失败告终了!😔不过源程序我一直保留着。😉
2、正在入门C#的我看到这个程序,果断fork,或许会看不懂,不过……总会有用的!喏!这是一个模拟人操作的程序,模拟复制,模拟鼠标点击提交,缺点就是,如果程序是后台运行便会停止~( ╯□╰ )……表示并不是自己想要的那一种……
3、博主还是用C#写的,50%的AC率看起来好”*/¥#“,只是没有开源,貌似自己在YTU OJ上的AC率只有56%。😣
4、用 node 来模拟用户的这个过程,其实就是一个 模拟登录+模拟提交 的过程,根据经验,模拟提交这个 post 过程肯定会带有 cookie。提交的 code 哪里来呢?直接爬取搜索引擎就好了。整个思路非常清晰:模拟登录(post),从搜索引擎爬取 code(get),模拟提交(post)。那这个是不是看起来很不错呢?对,只是Node普通环境我通过baidu找教程配置好了,然而还是不能运行,估计还缺少一个什么环境吧!只有一百多行代码写出的AC机果然不容小觑,运行不了……【笑哭】【笑哭】【笑哭】
正文
至于网上找的,终究不如自己写的,那么,先上图!
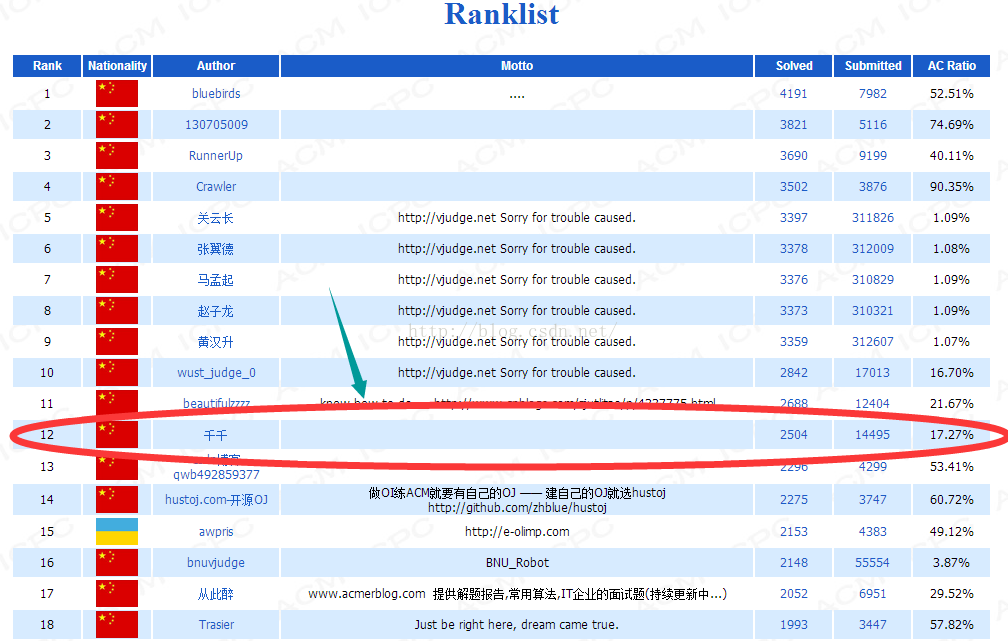
第12名的千千是我哦!
请忽略我的正确率,相比学长做的那些,还是差了很多……不过,先给各位辛苦刷题的ACMer赔个不是,毕竟这是很投机的一种方式,仅供娱乐,还请各位见谅!
下面我们一步一步开始AUTO AC之旅吧!
1、同样使用socket编程模拟HTTP协议GET请求向服务器发送页面请求
string reqInfo = "POST " + (string)othPath + " HTTP/1.1rnHost: " + (string)host + ElseInfo + Typee + ConLen + (string)s + "rnCookie: " + Cookie + "rnConnection:Closernrn" + ResCode;
if (SOCKET_ERROR == send(sock, reqInfo.c_str(), reqInfo.size(), 0))
{
cout << "send error! 错误码: " << WSAGetLastError() << endl;
closesocket(sock);
}我们使用Socket编程通过bind(),connect(),send(),recv()这些函数建立与服务器的连接。 接下来我们想:点击按钮的过程发生了什么,我们使用send()需要将什么信息发送至服务器,这里就要涉及到HTTP协议的GET请求。
2、借助搜索引擎获取csdn博客链接
先上几张图~
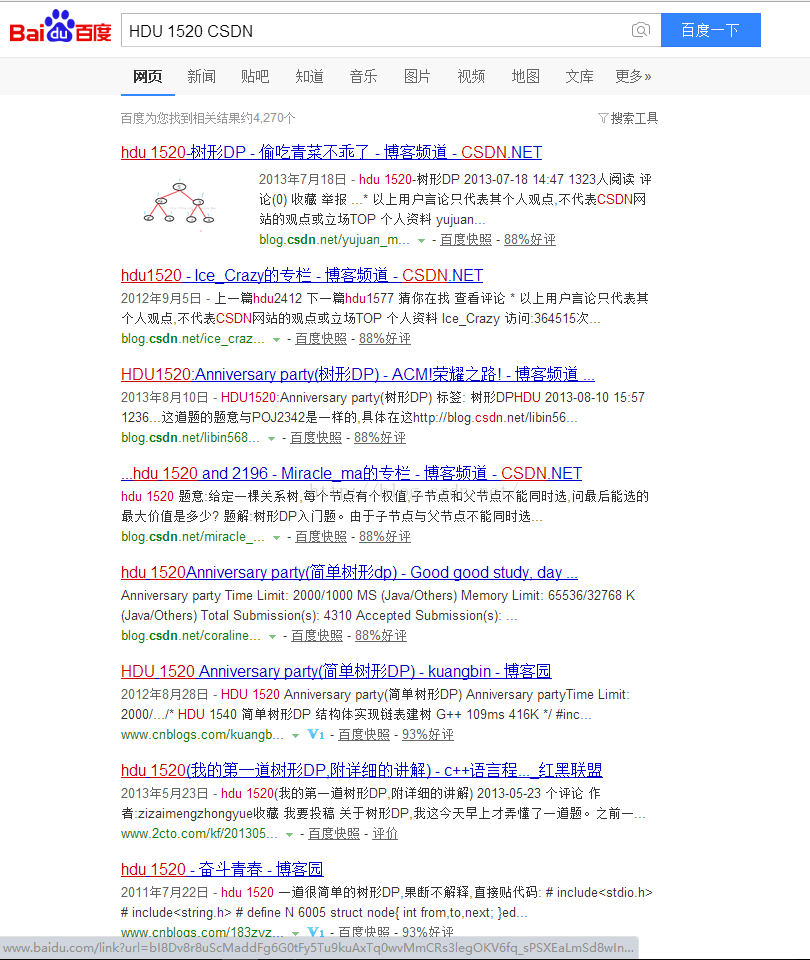
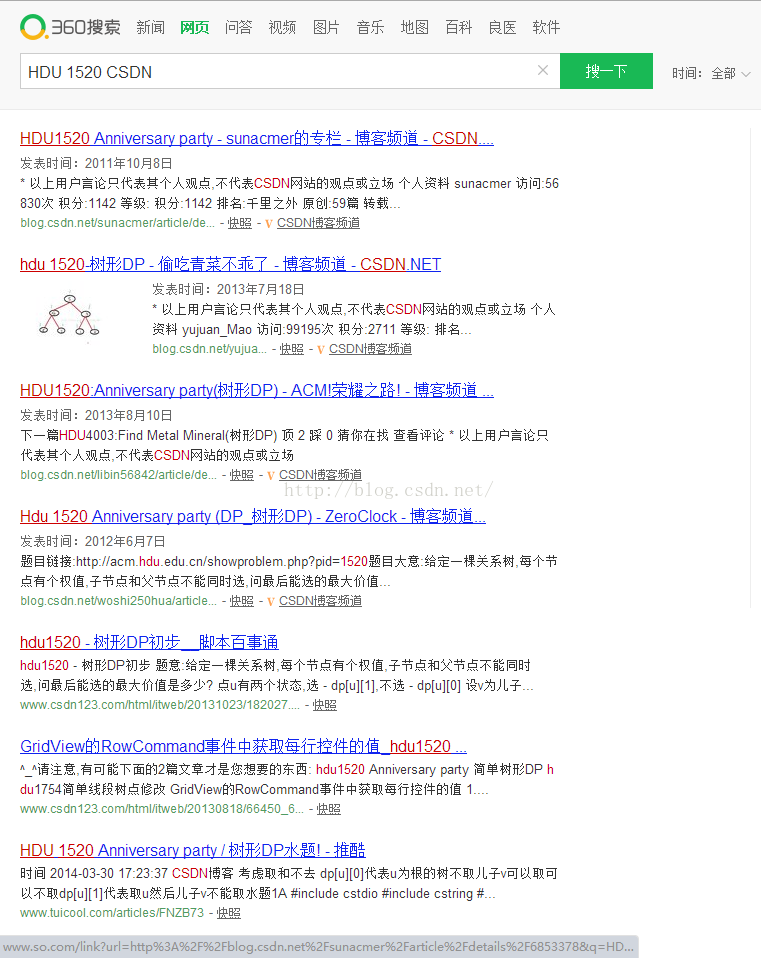
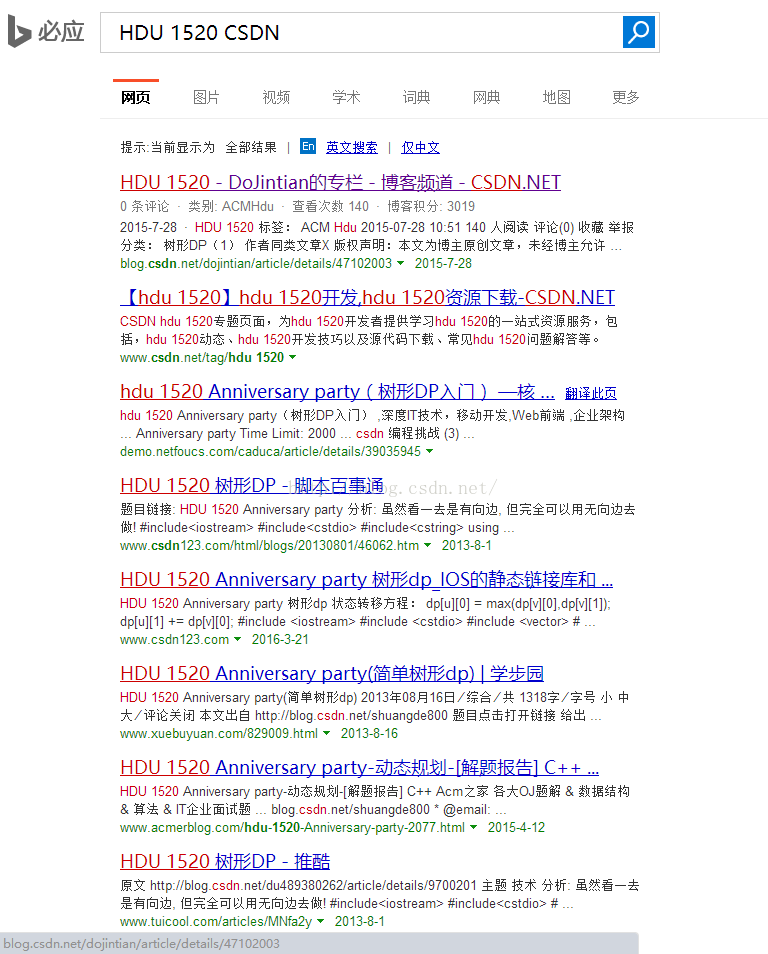
看到这些不同的搜索引擎所搜索的结果,你有什么发现么?
没错,注意左下角哦!百度和360的搜索引擎都对链接做了加密处理,对于这样的链接,我们从源代码中是很难提取对应页面的原始地址的!所以最终找到了必应搜索引擎(有道搜索也可以),不过,缺点就是这些对于我们来说不太常用的搜索引擎对我们想要的页面的索引量也不是很多。不过,够用了~
有没有人想问我为什么不用CSDN内置的搜索呢?我只能说,CSDN的搜索引擎还没有我自己写的find函数好用😇,有时候站内搜索已有的文章也搜索不到!
void GetCSDNurl(string &allHtml) ///提取网页中的csdn博客网址
{
blogUrl.clear();
smatch mat;
regex pattern("href="(http://blog.csdn[^\s"]+)"");
string::const_iterator start = allHtml.begin();
string::const_iterator end = allHtml.end();
while (regex_search(start, end, mat, pattern))
{
string msg(mat[1].first, mat[1].second);
blogUrl.push_back(msg);
start = mat[0].second;
}
}
曾经用PHP做<微信公众平台:imqxms> 的后台的时候用过正则表达式,结果发现C++中也有。所以直接找学长的源码为我所用啦!(说出名称只求你的关注:imqxms)
3、从HTML源代码中提取程序代码
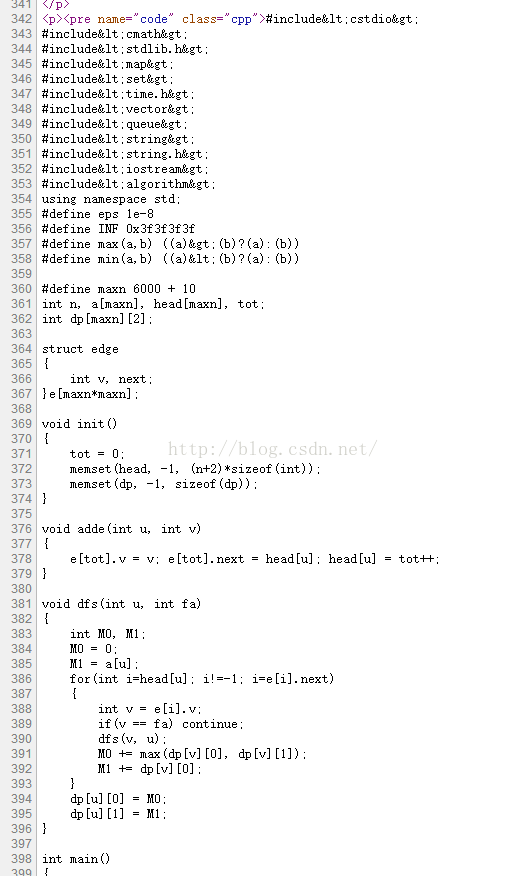
这张图片是网页源代码中的程序代码部分!
明显的特征就是我们常用的#include<>😝,可以看到,'<‘与’>’等一些字符都被改成了其他字符,这或许是网络标记语言中的转义字符吧!
void GetCode(string &allHtml) //提取代码部分
{
CodeHtml = "";
int pos = allHtml.find("#include");
if (pos != string::npos)
{
for (int i = pos; i < (int)allHtml.length(); i++)
{
if ((allHtml[i] == '<'&&allHtml[i + 1] == '/'&&allHtml[i + 2] == 't'&&allHtml[i + 3] == 'e'&&allHtml[i + 4] == 'x'&&allHtml[i + 5] == 't'))return;
else if (allHtml[i] == '<'&&allHtml[i + 1] == '/'&&allHtml[i + 2] == 'p'&&allHtml[i + 3] == 'r'&&allHtml[i + 4] == 'e'&&allHtml[i + 5] == '>')return;
CodeHtml += allHtml[i];
}
}
else
{
cout << "未找到合适的代码!" << endl;
return;
}
}
我们需要的是原来完整的代码,那么,接下来的任务就是将这段程序中所有的HTML转义字符转换成C++或者其他语言中的字符咯!
另外讲一下几个关于网页表单很重要的编码。
一个是url编码,因为如果要传送的数据中包含一些符号,可能会对原本的文本的分隔符产生冲突,比如& / =等一些用于地址的符号,所以需要把这些符号转义
网页中都是利用url编码进行转义的。
然后一个问题就是网页的编码,分gb2312和utf-8两种
gb2312是中文编码,utf-8是一种更普遍的面向更多语言的编码,两种编码在字母的ASCII码上,是一样的
但是在中文汉字上,gb2312是占2个字节,utf-8占3个字节,这也会导致两种编码下的内容url编码之后会不一样
因此我们还需要做一个对不同编码进行转换的函数!
char* U2G(const char* utf8) ///UTF-8 to GB2312
{
int len = MultiByteToWideChar(CP_UTF8, 0, utf8, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_UTF8, 0, utf8, -1, wstr, len);
len = WideCharToMultiByte(CP_ACP, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, wstr, -1, str, len, NULL, NULL);
if (wstr) delete[] wstr;
return str;
}
char* G2U(const char* gb2312) ///GB2312 TO UTF-8
{
int len = MultiByteToWideChar(CP_ACP, 0, gb2312, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_ACP, 0, gb2312, -1, wstr, len);
len = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_UTF8, 0, wstr, -1, str, len, NULL, NULL);
if (wstr) delete[] wstr;
return str;
}
喏,就是这个,百度(Bing)就是好用✌
string HTMLTOC(string &CodeHtml) ///HTML转义字符转义处理
{
string ans;
for (int i = 0; i < (int)CodeHtml.length(); i++)
{
if (CodeHtml[i] == '&'&&CodeHtml[i + 1] == 'l'&&CodeHtml[i + 2] == 't'&&CodeHtml[i + 3] == ';') ///< <
{
ans += '<';
i += 3;
}
else if (CodeHtml[i] == '&'&&CodeHtml[i + 1] == 'g'&&CodeHtml[i + 2] == 't'&&CodeHtml[i + 3] == ';') ///> >
{
ans += '>';
i += 3;
}
else if (CodeHtml[i] == '/'&&CodeHtml[i + 1] == 'n') /// /n; \n
{
ans += "\n";
i += 1;
}
else if (CodeHtml[i] == '&'&&CodeHtml[i + 1] == 'a'&&CodeHtml[i + 2] == 'm'&&CodeHtml[i + 3] == 'p'&&CodeHtml[i + 4] == ';') ///& &
{
ans += '&';
i += 4;
}
else if (CodeHtml[i] == '&'&&CodeHtml[i + 1] == 'q'&&CodeHtml[i + 2] == 'u'&&CodeHtml[i + 3] == 'o'&&CodeHtml[i + 4] == 't'&&CodeHtml[i + 5] == ';') ///" "
{
ans += '"';
i += 5;
}
else if (CodeHtml[i] == '&'&&CodeHtml[i + 1] == 'n'&&CodeHtml[i + 2] == 'b'&&CodeHtml[i + 3] == 's'&&CodeHtml[i + 4] == 'p'&&CodeHtml[i + 5] == ';') /// ' '
{
ans += ' ';
i += 5;
}
else if (CodeHtml[i] == '&'&&CodeHtml[i + 1] == '#'&&CodeHtml[i + 2] == '4'&&CodeHtml[i + 3] == '3'&&CodeHtml[i + 4] == ';') ///+ +
{
ans += '+';
i += 4;
}
else if (CodeHtml[i] == '&'&&CodeHtml[i + 1] == '#'&&CodeHtml[i + 2] == '3'&&CodeHtml[i + 3] == '9'&&CodeHtml[i + 4] == ';') ///' ''
{
ans += ''';
i += 4;
}
else ans += CodeHtml[i];
}
return ans;
}
好诧异为什么有的学长写的代码中没有这一部分,难道说……[撇嘴],,其实,有一个问题,上面的代码实现了字符的转换,可是这种算法和KMP模式匹配哪种更好呢?
我不会告诉你我昨晚C语言结课考试的时候也有这么一道题(把句子中所有的don’t 替换成do not),用的也是上面的方法!
—————————貌似已经说了,( ╯□╰ )……
4、利用网页中的cookie来模拟在线
因为每一个账号登录之后都会有唯一的一个cookie,那种模拟鼠标点击的程序,实质上是一个浏览器,可是我在控制台下不会做到这些😭,所以做出来的AC机只能在你用浏览器打开的情况下,并且你的账号在线的情况下才能运行😔
string Cookie = "exesubmitlang=2; PHPSESSID=" + PHPSESSID + "; CNZZDATA1254072405=" + CNZZDATA;
string reqInfo = "POST " + (string)othPath + " HTTP/1.1rnHost: " + (string)host + ElseInfo + Typee + ConLen + (string)s + "rnCookie: " + Cookie + "rnConnection:Closernrn" + ResCode;
说到Cookice,想要查看你在浏览器中的Cookice信息,以谷歌浏览器为例,鼠标右键>>检查里面有惊喜哦!
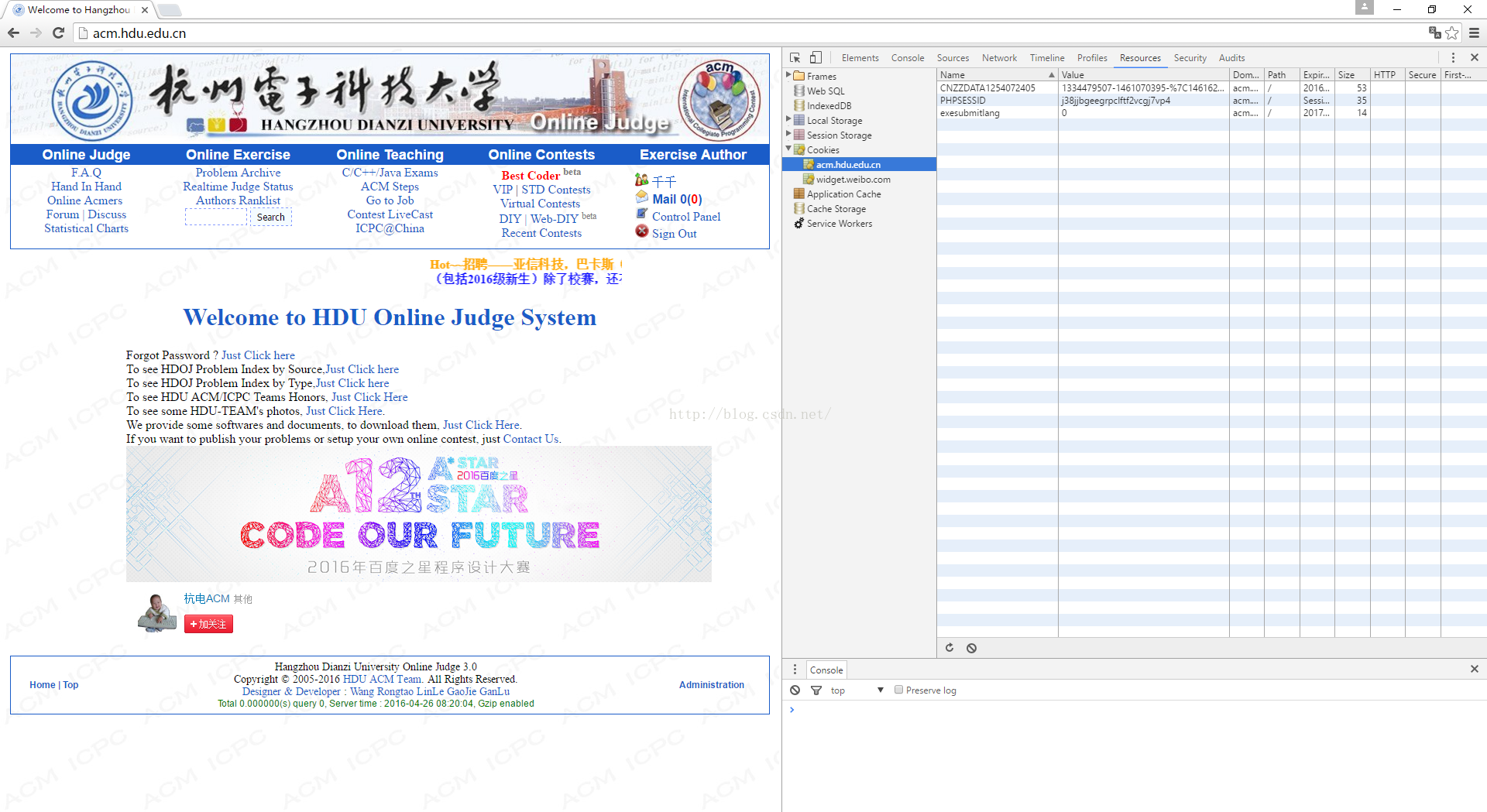
用来刷题的是我的小号😏
5、既然能做到从网页中提取一个程序的源代码,那么,我也可以在HDU OJ的状态栏找到我们提交之后的最终结果咯!
void GetResult(string &allHtml, int Prob) ///解析出state.php中的结果,空间,时间
{
StateAns = "", StateSapce = "", StateTime = "";
char d[200];
_itoa(ProblemID, d, 10);
strcat(d, "");
int pos = allHtml.find((string)d);
int Mpos = pos;
int Tpos;
if (Mpos == string::npos)return;
else
{
Mpos += 17;
while (true)
{
if (allHtml[Mpos] == '<')
{
Tpos = Mpos;
break;
}
StateSapce += allHtml[Mpos];
Mpos++;
}
cout << "空间: " << StateSapce << endl;
}
Tpos += 9;
while (true)
{
if (allHtml[Tpos] == '<')break;
StateTime += allHtml[Tpos];
Tpos++;
}
cout << "耗时: " << StateTime << endl;
if (pos == string::npos)return;
else
{
pos = pos - 52;
int begin;
while (true)
{
if (allHtml[pos] == '>')
{
begin = pos;
break;
}
pos--;
}
for (int i = begin + 1; allHtml[i] != '<'; i++)StateAns += allHtml[i];
}
cout << "结果: " << "---------------::::::" << StateAns << endl;
}
if(StateAns==”Accepted“)break;//如果AC,跳出本次循环,也就是执行下一道题目!
6、别忘了在你的循环后面加上Sleep函数哦!
不然那个状态页面整个页面都会是你的提交。
貌似我曾经因为没有Sleep,然后被不认识的人加了好友【撇嘴】,并不知道他是怎么加到我的!然后告诉我看到我在航电上面刷题了,所以问了我几道题 😐
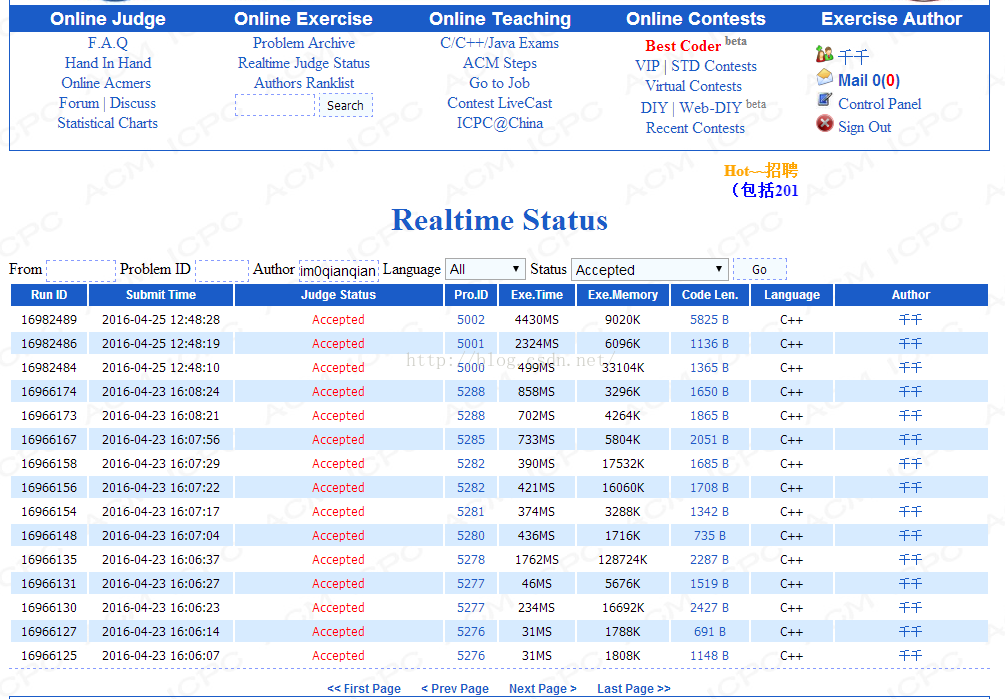
有的人或许会问,HDU上面不是有1000-5674个题目吗?为什么你总共才AC了两千多道题目,对于这个问题,只能怪我算法没有好好优化,或许可以去ACM之家找源码哦!
7、可执行文件在我的GitHub里面,欢迎大家Fork,别刷太快哦!不然会超过我的。。。【祈求】【祈求】【祈求】😭
至于源码,以后放出吧! 已放出 千千好委屈,但千千不说!
后记
期待你的留言与评论哦!😋
前段时间有人说我的博客不能留言了,不知道是不是真的……o(* ̄▽ ̄*)ブ



你好,为什么我的杭电oj里面的cookie中没有’CNZZDATA’这个项目呢?
这是站长统计需要的一个 cookie,可能 HDU 最后去掉了这个所以没有了
那没有了这个之后自动机就是用不了的吗,我下载了你GitHub上的项目,要’CNZZDATA’后才能运行,我想问一下这个对于自动机是必须的吗,没有这个可以设计自动机吗
应该不影响的,这个项目是好几年前做的,已经不太记得了,你可以试试。
我也想要有这样的一个博客站,能求教吗?
网上有很多教程,建议先去查查看